a站app青岛网络推广公司
本文章转载于公众号:王清江唷,仅用于学习和讨论,如有侵权请联系
QQ交流群:298405437
本人QQ:4206359 具体视频地址:8 跑后端_哔哩哔哩_bilibili
1、HTTP?
曾经我们在讲JWT的时候,当时JWT需要配合https使用呢?
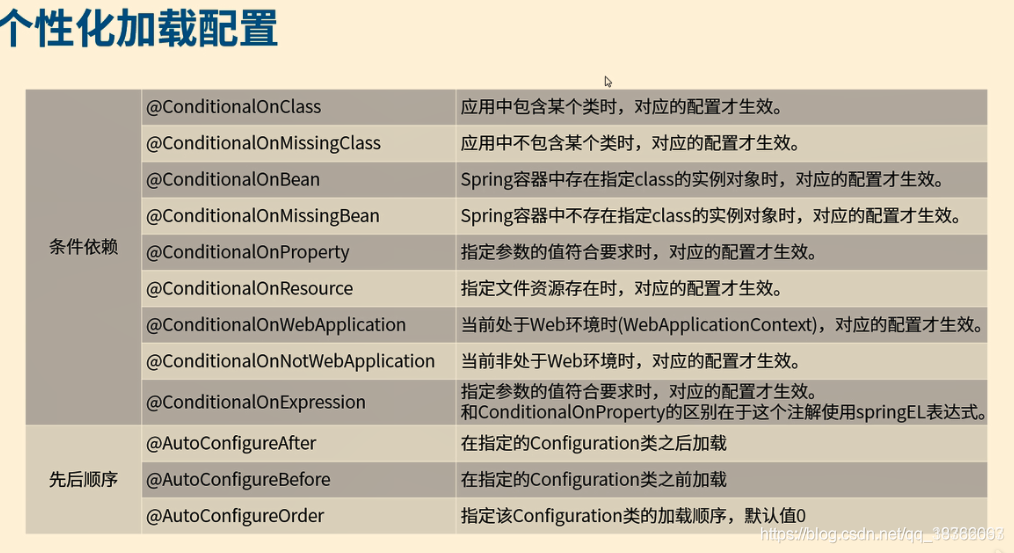
因为http自身是明码传输,我们通过网卡抓包可以轻而易举得到token。
我们的token相当于在网络上明码传输,很容易被人拦截查看!
下面演示一下拦截token!
效果图:
2、不安全怎么办呐?
既然不安全,那咋办呢?上https!
视频演示腾讯云上https。
3、HTTPs实现
现在我们利用腾讯云实现HTTPs。
首先得有一个域名吧?怎么买我就不多说了,直接在腾讯云搜索域名,选择自己喜欢的购买。
然后呢,还需要购买SSL证书,一般来说,买域名会送一个SSL证书,反正我的是送的。如果没送可以点击申请免费证书,证书界面如下:
https://console.cloud.tencent.com/ssl
有了证书之后,我们需要先下载证书,下载nginx证书。请直接看视频。
腾讯云官方学习视频:
https://cloud.tencent.com/document/product/400/35244
把打包下载的证书直接全部丢到nginx/conf文件夹,然后改写nginx配置文件:
user www;worker_processes auto;error_log /www/wwwlogs/nginx_error.log crit;pid /www/server/nginx/logs/nginx.pid;worker_rlimit_nofile 51200;events{use epoll;worker_connections 51200;multi_accept on;}http {include mime.types;default_type application/octet-stream;sendfile on;keepalive_timeout 65;client_max_body_size 100m;#用于tomcat反向代理,解决nginx 504错误proxy_connect_timeout 7200; #单位秒proxy_send_timeout 7200; #单位秒proxy_read_timeout 7200; #单位秒proxy_buffer_size 16k;proxy_buffers 4 64k;proxy_busy_buffers_size 128k;proxy_temp_file_write_size 128k;# ps:以timeout结尾配置项时间要配置大点server {listen 80;server_name localhost;charset utf-8;location / {root /home/wqj/dist;try_files $uri $uri/ /index.html;index index.html index.htm;}location /prod-api/ {proxy_set_header Host $http_host;proxy_set_header X-Real-IP $remote_addr;proxy_set_header REMOTE-HOST $remote_addr;proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;proxy_pass http://localhost:8765/;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}server {#SSL 默认访问端口号为 443listen 443 ssl;#请填写绑定证书的域名server_name wangqingjiang.top;#请填写证书文件的相对路径或绝对路径ssl_certificate wangqingjiang.top_bundle.crt;#请填写私钥文件的相对路径或绝对路径ssl_certificate_key wangqingjiang.top.key;ssl_session_timeout 5m;#请按照以下协议配置ssl_protocols TLSv1.2 TLSv1.3;#请按照以下套件配置,配置加密套件,写法遵循 openssl 标准。ssl_ciphers ECDHE-RSA-AES128-GCM-SHA256:HIGH:!aNULL:!MD5:!RC4:!DHE;ssl_prefer_server_ciphers on;charset utf-8;location / {root /home/wqj/dist;try_files $uri $uri/ /index.html;index index.html index.htm;}location /prod-api/ {proxy_set_header Host $http_host;proxy_set_header X-Real-IP $remote_addr;proxy_set_header REMOTE-HOST $remote_addr;proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;proxy_pass http://localhost:8765/;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}
}
回头再看,其实就是一些固定的配置。然后重启nginx之后就发现https已经生效:
后来抓的包我就没读懂过:
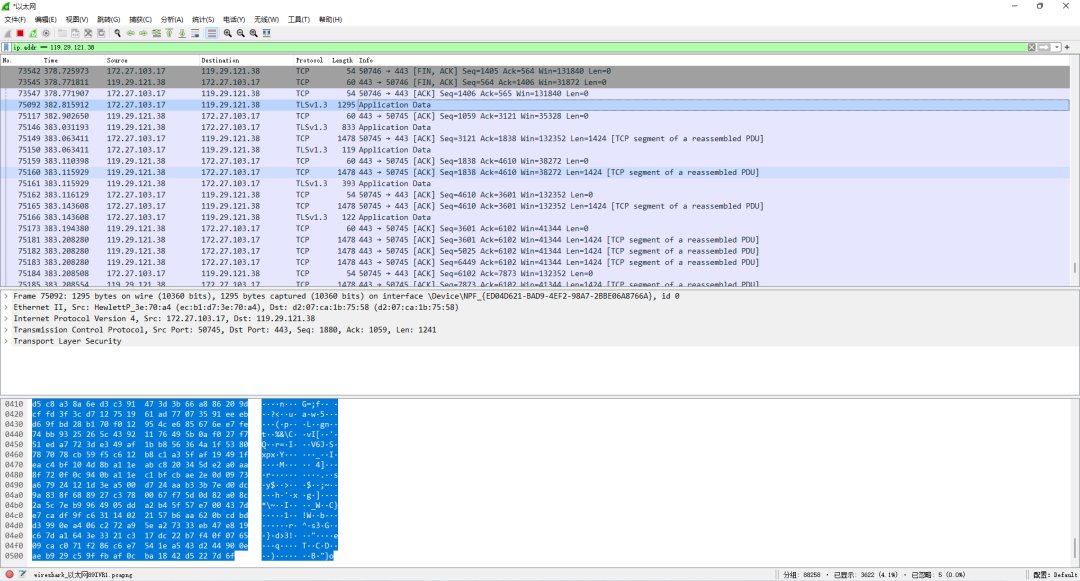
4、分页的前端配置
接下来以操作日志页面为例子,进行讲述。
前端每次给后端发请求的时候,都是带了分页参数的,默认都是请求第一页,每页10条数据。源码:
//请求参数:queryParams: {pageNum: 1,pageSize: 10,title: undefined,operName: undefined,businessType: undefined,status: undefined}//每次 发送请求带上了分页参数的:/** 查询登录日志 */getList() {this.loading = true;list(this.addDateRange(this.queryParams, this.dateRange)).then( response => {this.list = response.rows;this.total = response.total;this.loading = false;});
},
ry对elementUI的分页组件进行了小小的封装:
<template><div :class="{'hidden':hidden}" class="pagination-container"><el-pagination:background="background":current-page.sync="currentPage":page-size.sync="pageSize":layout="layout":page-sizes="pageSizes":pager-count="pagerCount":total="total"v-bind="$attrs"@size-change="handleSizeChange"@current-change="handleCurrentChange"/></div></template><script>import { scrollTo } from '@/utils/scroll-to'export default {name: 'Pagination',props: {total: {required: true,type: Number},page: {type: Number,default: 1},limit: {type: Number,default: 20},pageSizes: {type: Array,default() {return [10, 20, 30, 50]}},// 移动端页码按钮的数量端默认值5pagerCount: {type: Number,default: document.body.clientWidth < 992 ? 5 : 7},layout: {type: String,default: 'total, sizes, prev, pager, next, jumper'},background: {type: Boolean,default: true},autoScroll: {type: Boolean,default: true},hidden: {type: Boolean,default: false}},data() {return {};},computed: {currentPage: {get() {return this.page},set(val) {this.$emit('update:page', val)}},pageSize: {get() {return this.limit},set(val) {this.$emit('update:limit', val)}}},methods: {handleSizeChange(val) {if (this.currentPage * val > this.total) {this.currentPage = 1}this.$emit('pagination', { page: this.currentPage, limit: val })if (this.autoScroll) {scrollTo(0, 800)}},handleCurrentChange(val) {this.$emit('pagination', { page: val, limit: this.pageSize })if (this.autoScroll) {scrollTo(0, 800)}}}}</script><style scoped>.pagination-container {background: #fff;padding: 32px 16px;}.pagination-container.hidden {display: none;}
</style>
我们跟着elementUI学习一下分页插件即可:
https://element.eleme.cn/#/zh-CN/component/pagination
参考学习资料:
https://blog.csdn.net/chenxi_li/article/details/118682708
我们看到了,前端只需要维护好数据,我需要当前是第几页,一共有几条数据,每页多少条。
前端只需要维护好这三个数据,其他的交给后端就行了。
4.1后端分页实现pagehelper
后端是通过pagehelper插件实现的。
ry通过pagehelper间接引入了mybatis:
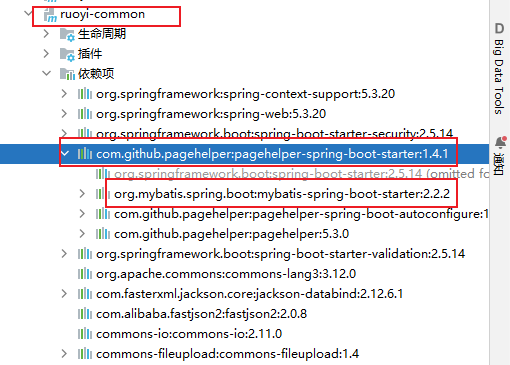
现在我们需要学习一波pagehelper的使用。
这就不得不介绍一波pagehelper的官网了:
https://pagehelper.github.io/docs/howtouse/
通过官网,我们需要知道为啥ry引入了分页插件就可以使用了,难道没有配置吗?
确实,如果使用了SpringBoot可以零配置。我们先通过创建一个新的项目零配置来使用一下pagehelper:
通过官网讲述常见的下面的分页方式:
// //第二种,Mapper接口方式的调用,推荐这种使用方式。//获取第1页,10条内容,默认查询总数count// ry用的就是下面这种。PageHelper.startPage(1, 10);//第五种,参数对象//如果 pageNum 和 pageSize 存在于 User 对象中,只要参数有值,也会被分页//有如下 User 对象public class User {//其他fields//下面两个参数名和 params 配置的名字一致private Integer pageNum;private Integer pageSize;}//支持 ServletRequest,Map,POJO 对象,需要配合 params 参数// 1、如果是request 则需要请求的时候带上对应的参数。// 2、如果是Map 则Map中需要包含pageNum,pageSize等选项。// 3、如果是POJO 则需要在pojo中带上对应的属性。PageHelper.startPage(request);
通过官网讲解常见的几种分页方式:
PageHelper.startPage传普通参数(ry使用的)。
PageHelper.startPage方法传POJO或Map或ServletRequest。
分析pagehelper源码
首先是需要分析分页拦截器。
分页插件在哪进行注入到SqlSessionFactory的?
这就不得不提到两个主动配置的类了:
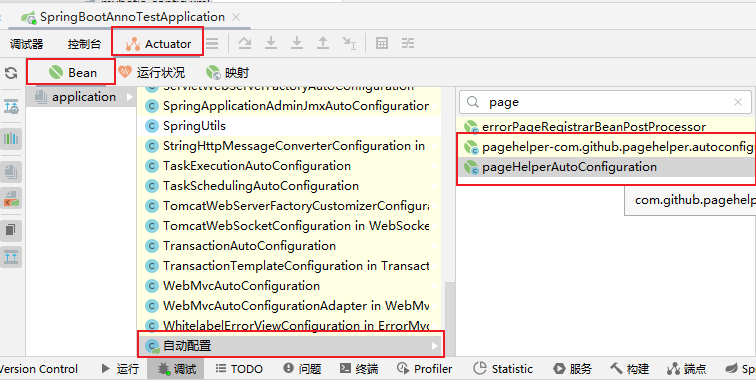
其中PageHelperProperties是为了去yml取出相应的配置,以供PageHelperAutoConfiguration在执行构造方法的时候找到。
PageHelperAutoConfiguration实现了InitializingBean接口,所以重写了afterPropertiesSet方法,该方法会在构造方法执行后执行。
接下来打俩断点,看看执行过程:
我们的yml配置是这样写的:
pagehelper:helperDialect: mysqlsupportMethodsArguments: trueparams: count=countSqldebug的时候需要注意,以上参数的默认值是什么?【debug讲述】
经过debug发现其实ry设置的几个参数全部不设置也可以。
helperDialect如果不设置,程序每次执行SQL都要分析方言,何不索性告诉分页插件,这样也让程序执行略快一点。
supportMethodsArguments虽然设置了,但是其实ry中根本没用过。
params设置了个寂寞,原本默认就是count=countSql,本来就是默认值,设置也是白设置。
分析ry如何使用pagehelper
ry在BaseController中封装了分页方法。也就是说我们自己写的controller只要继承了BaseController,直接调用startPage方法即可完成分页。
ry的分页源码也非常简单:
/*** 设置请求分页数据*/public static void startPage(){PageDomain pageDomain = TableSupport.buildPageRequest();Integer pageNum = pageDomain.getPageNum();Integer pageSize = pageDomain.getPageSize();String orderBy = SqlUtil.escapeOrderBySql(pageDomain.getOrderBy());Boolean reasonable = pageDomain.getReasonable();PageHelper.startPage(pageNum, pageSize, orderBy).setReasonable(reasonable);}
从源码可以发现,无非就是从请求中拿到从前端传来的pageNum,pageSize,reasonable,orderBy和isAsc这些分页参数,然后直接调用分页插件pagehelper的静态分页方法PageHelper.startPage。
5、ry中的Mybatis详解
5.1 mybatis和SpringBoot结合方式
经过以前的经验,我们直接看mybatis的自动配置类:
@Bean@ConditionalOnMissingBeanpublic SqlSessionFactory sqlSessionFactory(DataSource dataSource) throws Exception {SqlSessionFactoryBean factory = new SqlSessionFactoryBean();factory.setDataSource(dataSource);factory.setVfs(SpringBootVFS.class);if (StringUtils.hasText(this.properties.getConfigLocation())) {factory.setConfigLocation(this.resourceLoader.getResource(this.properties.getConfigLocation()));}applyConfiguration(factory);if (this.properties.getConfigurationProperties() != null) {factory.setConfigurationProperties(this.properties.getConfigurationProperties());}if (!ObjectUtils.isEmpty(this.interceptors)) {factory.setPlugins(this.interceptors);}if (this.databaseIdProvider != null) {factory.setDatabaseIdProvider(this.databaseIdProvider);}if (StringUtils.hasLength(this.properties.getTypeAliasesPackage())) {factory.setTypeAliasesPackage(this.properties.getTypeAliasesPackage());}if (this.properties.getTypeAliasesSuperType() != null) {factory.setTypeAliasesSuperType(this.properties.getTypeAliasesSuperType());}if (StringUtils.hasLength(this.properties.getTypeHandlersPackage())) {factory.setTypeHandlersPackage(this.properties.getTypeHandlersPackage());}if (!ObjectUtils.isEmpty(this.typeHandlers)) {factory.setTypeHandlers(this.typeHandlers);}if (!ObjectUtils.isEmpty(this.properties.resolveMapperLocations())) {factory.setMapperLocations(this.properties.resolveMapperLocations());}Set<String> factoryPropertyNames = Stream.of(new BeanWrapperImpl(SqlSessionFactoryBean.class).getPropertyDescriptors()).map(PropertyDescriptor::getName).collect(Collectors.toSet());Class<? extends LanguageDriver> defaultLanguageDriver = this.properties.getDefaultScriptingLanguageDriver();if (factoryPropertyNames.contains("scriptingLanguageDrivers") && !ObjectUtils.isEmpty(this.languageDrivers)) {// Need to mybatis-spring 2.0.2+factory.setScriptingLanguageDrivers(this.languageDrivers);if (defaultLanguageDriver == null && this.languageDrivers.length == 1) {defaultLanguageDriver = this.languageDrivers[0].getClass();}}if (factoryPropertyNames.contains("defaultScriptingLanguageDriver")) {// Need to mybatis-spring 2.0.2+factory.setDefaultScriptingLanguageDriver(defaultLanguageDriver);}return factory.getObject();
}
可以发现,无非就是创建SqlSessionFactoryBean并且进行一系列配置之后,getObject得到SqlSessionFactory(实际是DefaultSqlSessionFactory对象)对象。
so,ry也是如此,重写了一个方法来获得sqlSessionFactory:
@Beanpublic SqlSessionFactory sqlSessionFactory(DataSource dataSource) throws Exception{String typeAliasesPackage = env.getProperty("mybatis.typeAliasesPackage");String mapperLocations = env.getProperty("mybatis.mapperLocations");String configLocation = env.getProperty("mybatis.configLocation");typeAliasesPackage = setTypeAliasesPackage(typeAliasesPackage);VFS.addImplClass(SpringBootVFS.class);final SqlSessionFactoryBean sessionFactory = new SqlSessionFactoryBean();sessionFactory.setDataSource(dataSource);sessionFactory.setTypeAliasesPackage(typeAliasesPackage);sessionFactory.setMapperLocations(resolveMapperLocations(StringUtils.split(mapperLocations, ",")));sessionFactory.setConfigLocation(new DefaultResourceLoader().getResource(configLocation));return sessionFactory.getObject();
}
在SpringBoot项目中,把SqlSessionFactory接口的实例注入到Spring容器中,mybatis的配置也就随之完成。
经过debug源码,发现本质上ry的注入SqlSessionFactory和原本的自动注入没什么差别,如果一定要说有差别,那就是亲自去扫描了别名包typeAliasesPackage。但其实必要性不大,框架自己也会去扫。
通过以上的说明,我们发现其实可以把ry的mybatis配置必要性并不大,可以完全删除ry自己配置的bean,发现一点也不影响当前项目的功能。
5.2mybatis-plus集成
关于mybatis-plus只是部分同学的需求,我们现在来做一下。做完再解释!
ry集成mybatis-plus最简秘诀
第一步,引入mybatis-plus,在common模块中:
<dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.5.2</version>
</dependency>
第二步,删除冲突依赖:
<!-- pagehelper 分页插件 --><dependency><groupId>com.github.pagehelper</groupId><artifactId>pagehelper-spring-boot-starter</artifactId><exclusions><exclusion><groupId>org.mybatis</groupId><artifactId>mybatis</artifactId></exclusion></exclusions>
</dependency>
第三步,填写yml配置:
mybatis-plus:configLocation: classpath:mybatis/mybatis-config.xml
typeAliasesPackage: com.ruoyi.**.domain
第四步,删除MyBatisConfig,也就是删除ry自己的配置文件,删除下面这个文件:
package com.wqj.test;import java.io.IOException;import java.util.ArrayList;import java.util.Arrays;import java.util.HashSet;import java.util.List;import javax.sql.DataSource;import com.baomidou.mybatisplus.autoconfigure.SpringBootVFS;import org.apache.commons.lang3.StringUtils;import org.apache.ibatis.io.VFS;import org.apache.ibatis.session.SqlSessionFactory;import org.mybatis.spring.SqlSessionFactoryBean;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import org.springframework.core.env.Environment;import org.springframework.core.io.DefaultResourceLoader;import org.springframework.core.io.Resource;import org.springframework.core.io.support.PathMatchingResourcePatternResolver;import org.springframework.core.io.support.ResourcePatternResolver;import org.springframework.core.type.classreading.CachingMetadataReaderFactory;import org.springframework.core.type.classreading.MetadataReader;import org.springframework.core.type.classreading.MetadataReaderFactory;import org.springframework.util.ClassUtils;/*** Mybatis支持*匹配扫描包** @author ruoyi*/@Configurationpublic class MyBatisConfig{@Autowiredprivate Environment env;static final String DEFAULT_RESOURCE_PATTERN = "**/*.class";public static String setTypeAliasesPackage(String typeAliasesPackage){ResourcePatternResolver resolver = (ResourcePatternResolver) new PathMatchingResourcePatternResolver();MetadataReaderFactory metadataReaderFactory = new CachingMetadataReaderFactory(resolver);List<String> allResult = new ArrayList<String>();try{for (String aliasesPackage : typeAliasesPackage.split(",")){List<String> result = new ArrayList<String>();aliasesPackage = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX+ ClassUtils.convertClassNameToResourcePath(aliasesPackage.trim()) + "/" + DEFAULT_RESOURCE_PATTERN;Resource[] resources = resolver.getResources(aliasesPackage);if (resources != null && resources.length > 0){MetadataReader metadataReader = null;for (Resource resource : resources){if (resource.isReadable()){metadataReader = metadataReaderFactory.getMetadataReader(resource);try{result.add(Class.forName(metadataReader.getClassMetadata().getClassName()).getPackage().getName());}catch (ClassNotFoundException e){e.printStackTrace();}}}}if (result.size() > 0){HashSet<String> hashResult = new HashSet<String>(result);allResult.addAll(hashResult);}}if (allResult.size() > 0){typeAliasesPackage = String.join(",", (String[]) allResult.toArray(new String[0]));}else{throw new RuntimeException("mybatis typeAliasesPackage 路径扫描错误,参数typeAliasesPackage:" + typeAliasesPackage + "未找到任何包");}}catch (IOException e){e.printStackTrace();}return typeAliasesPackage;}public Resource[] resolveMapperLocations(String[] mapperLocations){ResourcePatternResolver resourceResolver = new PathMatchingResourcePatternResolver();List<Resource> resources = new ArrayList<Resource>();if (mapperLocations != null){for (String mapperLocation : mapperLocations){try{Resource[] mappers = resourceResolver.getResources(mapperLocation);resources.addAll(Arrays.asList(mappers));}catch (IOException e){// ignore}}}return resources.toArray(new Resource[resources.size()]);}@Beanpublic SqlSessionFactory sqlSessionFactory(DataSource dataSource) throws Exception{String typeAliasesPackage = env.getProperty("mybatis.typeAliasesPackage");String mapperLocations = env.getProperty("mybatis.mapperLocations");String configLocation = env.getProperty("mybatis.configLocation");typeAliasesPackage = setTypeAliasesPackage(typeAliasesPackage);VFS.addImplClass(SpringBootVFS.class);final SqlSessionFactoryBean sessionFactory = new SqlSessionFactoryBean();sessionFactory.setDataSource(dataSource);sessionFactory.setTypeAliasesPackage(typeAliasesPackage);sessionFactory.setMapperLocations(resolveMapperLocations(StringUtils.split(mapperLocations, ",")));sessionFactory.setConfigLocation(new DefaultResourceLoader().getResource(configLocation));return sessionFactory.getObject();}
}
然后直接重启项目,成功!
解释疑问:
疑问一:为什么要排除pagehelper中的mybatis依赖?
答:因为mybatis-plus的启动器和pagehelper都引入了mybatis,mybatis-plus的启动器的mybatis版本比较高。
pagehelper引入的mybatis的版本比较低,mybatis-plus用到了高版本mybatis的方法。所以需要排除pagehelper中的mybatis。否则报错没找到方法。
疑问二:pagehelper中排除了mybatis,为啥不把mybatis-spring一块给排除掉?
答:确实可以一块排除掉,可以。但是mybatis-plus也引入了mybatis-spring,所以并不冲突,maven会自动排除一个。
疑问三:为啥在pagehelper中不把MybatisAutoConfiguration的依赖排除掉?不都有mybatis-plus了吗,我还要MybatisAutoConfiguration有啥用?
答:因为pagehelper的自动配置类用到了MybatisAutoConfiguration,虽然不起作用,但是也不能排除依赖,否则直接报【类没有找到异常】。那么在哪里用到的呢?
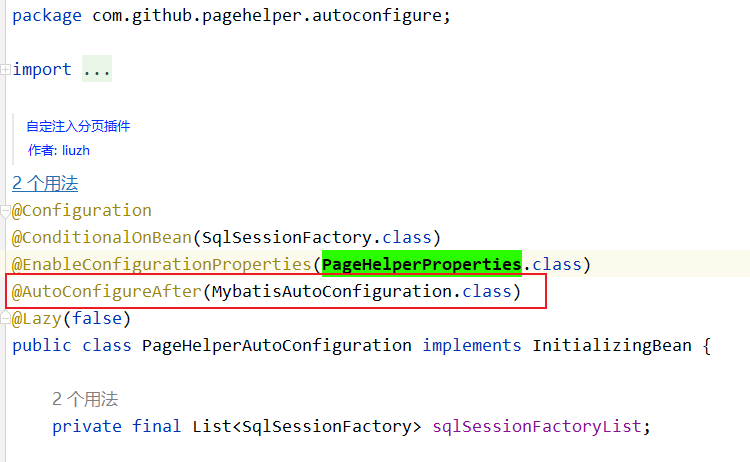
疑问四:为啥yml配置中不写mapperLocations的相关配置?
答:可以写,但是默认就是classpath*:mapper/**/*Mapper.xml,写不写都一样,相关源码:
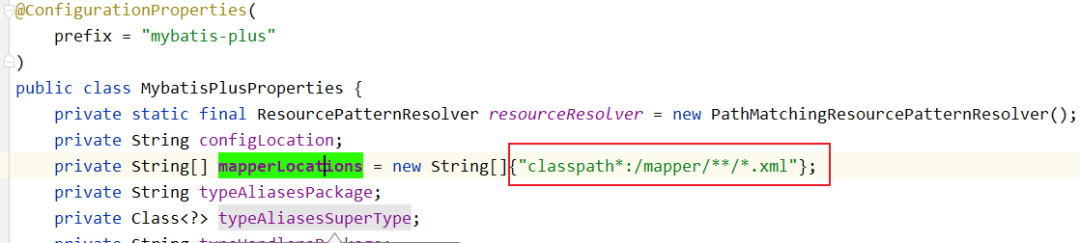
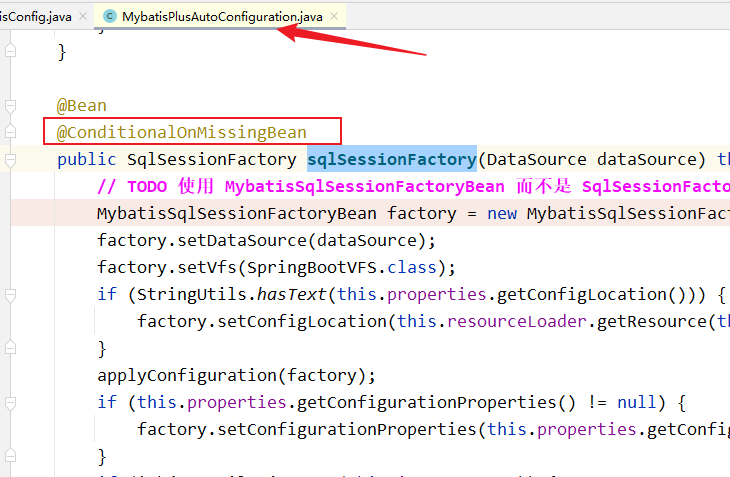
疑问五:为啥要删除原本的MybatisConfig?
答:因为原来的MybatisConfig会生成一个名字为sqlSessionFactory的bean,那么mybatis-plus的自动配置bean失效,因为mybatis-plus的自动配置加了注解@ConditionalOnMissingBean,也就是说sqlSessionFactory若存在,mybatis-plus则不会注入sqlSessionFactory。相关代码:
测试mybatis-plus
直接测试一波登录日志的查询!
先给mapper接口加buff:
public interface SysLogininforMapper extends BaseMapper<SysLogininfor>然后直接查询即可:
@Overridepublic List<SysLogininfor> selectLogininforList(SysLogininfor logininfor) {return logininforMapper.selectList(null);// return logininforMapper.selectLogininforList(logininfor);}
报错!
然后生成的SQL:
SELECTinfo_id,user_name,STATUS,ipaddr,login_location,browser,os,msg,login_time,search_value,create_by,create_time,update_by,update_time,remark,paramsFROMsys_logininforLIMIT ?
好玩的事情发生了,BaseEntity的属性也被写入了SQL中。对于这种残花败柳,我们直接标记它不存在:
/*** 搜索值*/@TableField(exist = false)private String searchValue;/*** 创建者*/@TableField(exist = false)private String createBy;/*** 创建时间*/@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss")@TableField(exist = false)private Date createTime;/*** 更新者*/@TableField(exist = false)private String updateBy;/*** 更新时间*/@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss")@TableField(exist = false)private Date updateTime;/*** 备注*/@TableField(exist = false)private String remark;/*** 请求参数*/@TableField(exist = false)private Map<String, Object> params;
随之查询成功,mp集成到此结束!
3►扩展学习
请大家自主学习下面注解的含义。
网站一:
https://wenku.baidu.com/view/20631ddf0142a8956bec0975f46527d3240ca624.html
网站二:
https://blog.csdn.net/Lou_Lan/article/details/106192074
网站三:
https://blog.csdn.net/weixin_43808717/article/details/118214615
网站四:
https://baijiahao.baidu.com/s?id=1740059649839757132&wfr=spider&for=pc
图片一(引用自csdn:):