优秀设计师网站天津快速关键词排名
前面我们的seata是在项目里面直接配置的。
我们是在每个微服务resources下创建一个file.conf文件。
这里我们改为把seata从nacos中获取配置。
1.我们把file.conf,放在resources下新建的backup_configs里面,废弃不用。
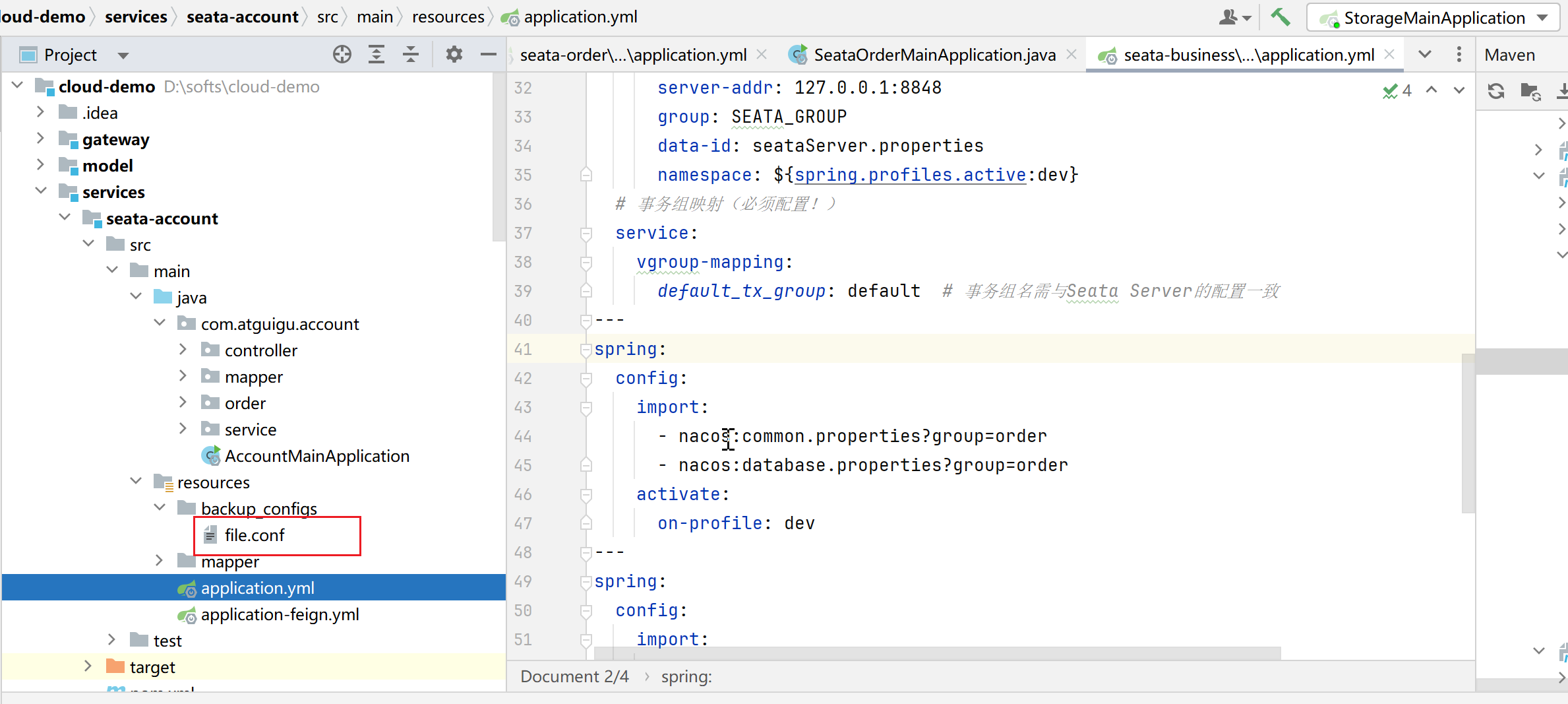
2. 修改seata配置
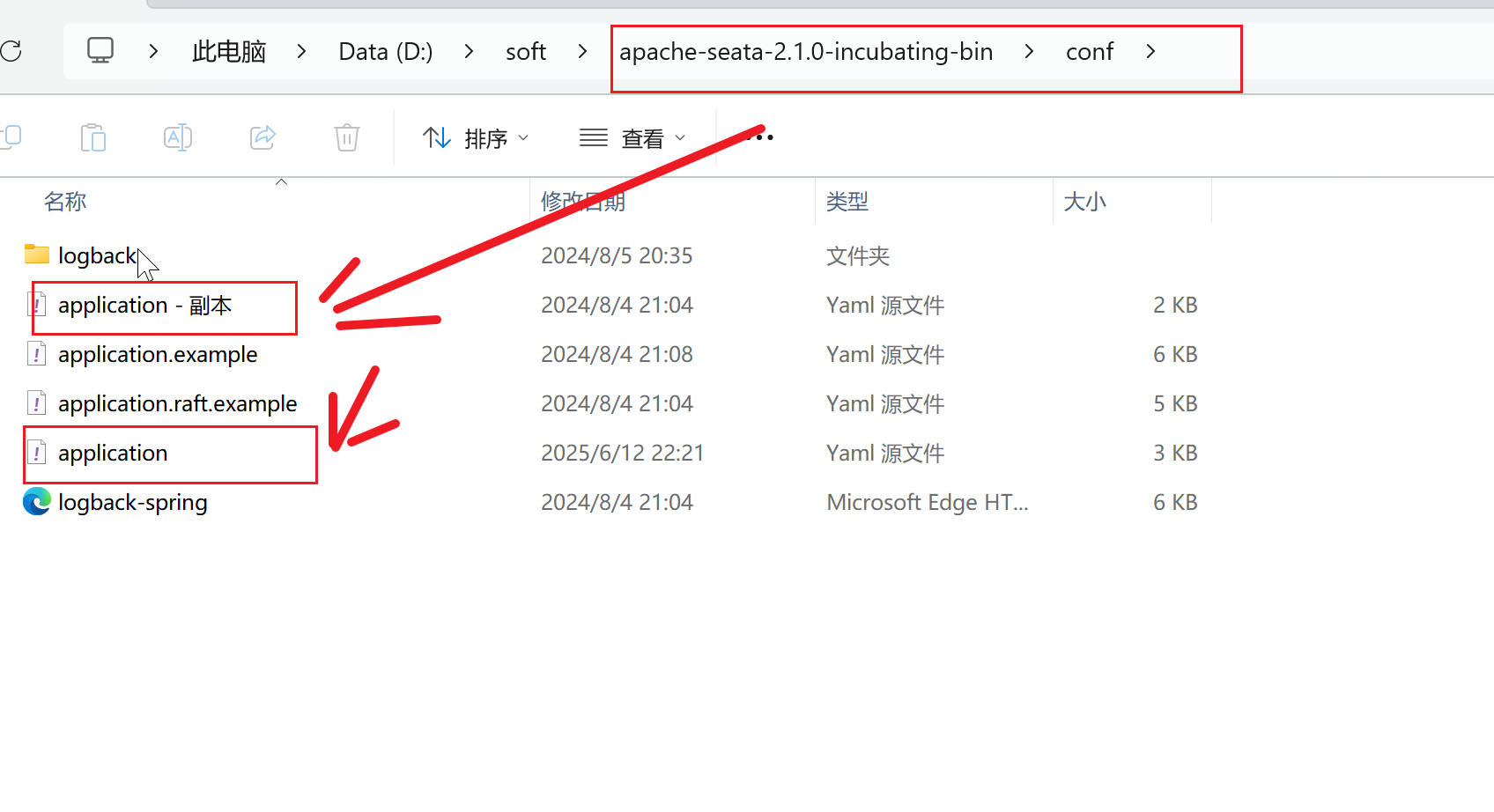
我们打开seata的文件夹,然后把application复制粘贴一份留痕。然后打开application 做如下修改:
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#server:port: 7091spring:application:name: seata-serverlogging:config: classpath:logback-spring.xmlfile:path: ${log.home:${user.home}/logs/seata}extend:logstash-appender:destination: 127.0.0.1:4560kafka-appender:bootstrap-servers: 127.0.0.1:9092topic: logback_to_logstashconsole:user:username: seatapassword: seata
seata:config:# support: nacos, consul, apollo, zk, etcd3type: nacosnacos:server-addr: 127.0.0.1:8848namespace: "dev"group: SEATA_GROUPdata-id: seataServer.propertiesusername: nacospassword: nacosregistry:# support: nacos, eureka, redis, zk, consul, etcd3, sofatype: nacosnacos:application: seata-serverserver-addr: 127.0.0.1:8848group: SEATA_GROUPnamespace: "dev"cluster: defaultusername: nacospassword: nacosstore:# support: file 、 db 、 redis 、 raftmode: dbdb:datasource: druiddb-type: mysqldriver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://127.0.0.1:3306/seata?useSSL=falseuser: xxxxpassword: yyyy# 替换为你的数据库密码# server:# service-port: 8091 #If not configured, the default is '${server.port} + 1000'security:secretKey: SeataSecretKey0c382ef121d778043159209298fd40bf3850a017tokenValidityInMilliseconds: 1800000ignore:urls: /,/**/*.css,/**/*.js,/**/*.html,/**/*.map,/**/*.svg,/**/*.png,/**/*.jpeg,/**/*.ico,/api/v1/auth/login,/version.json,/health,/error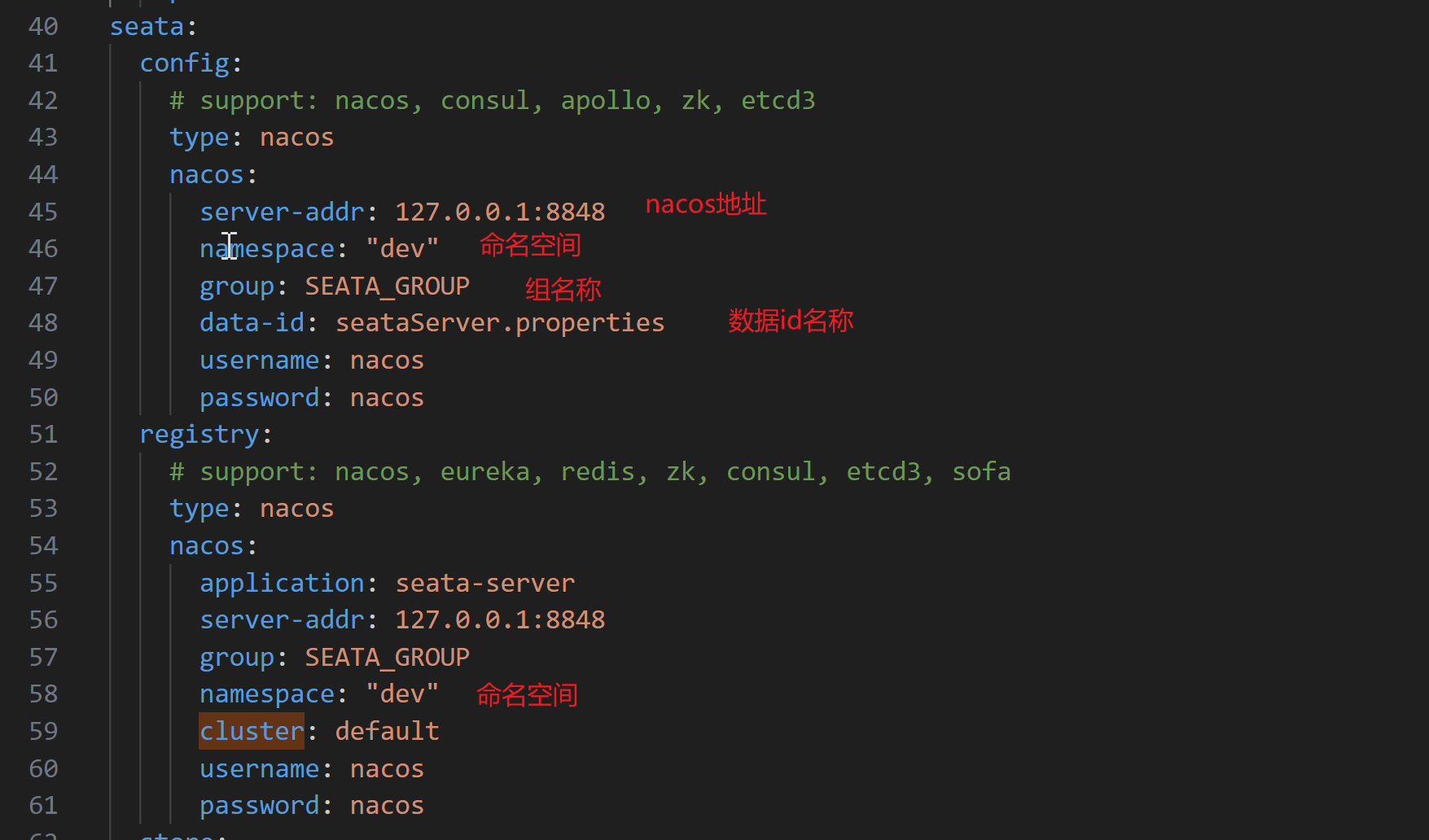
上面标注了下注释,客户看下。注意命名空间也是区分服务实例的范围之一,要与客户端的配置保持一致。
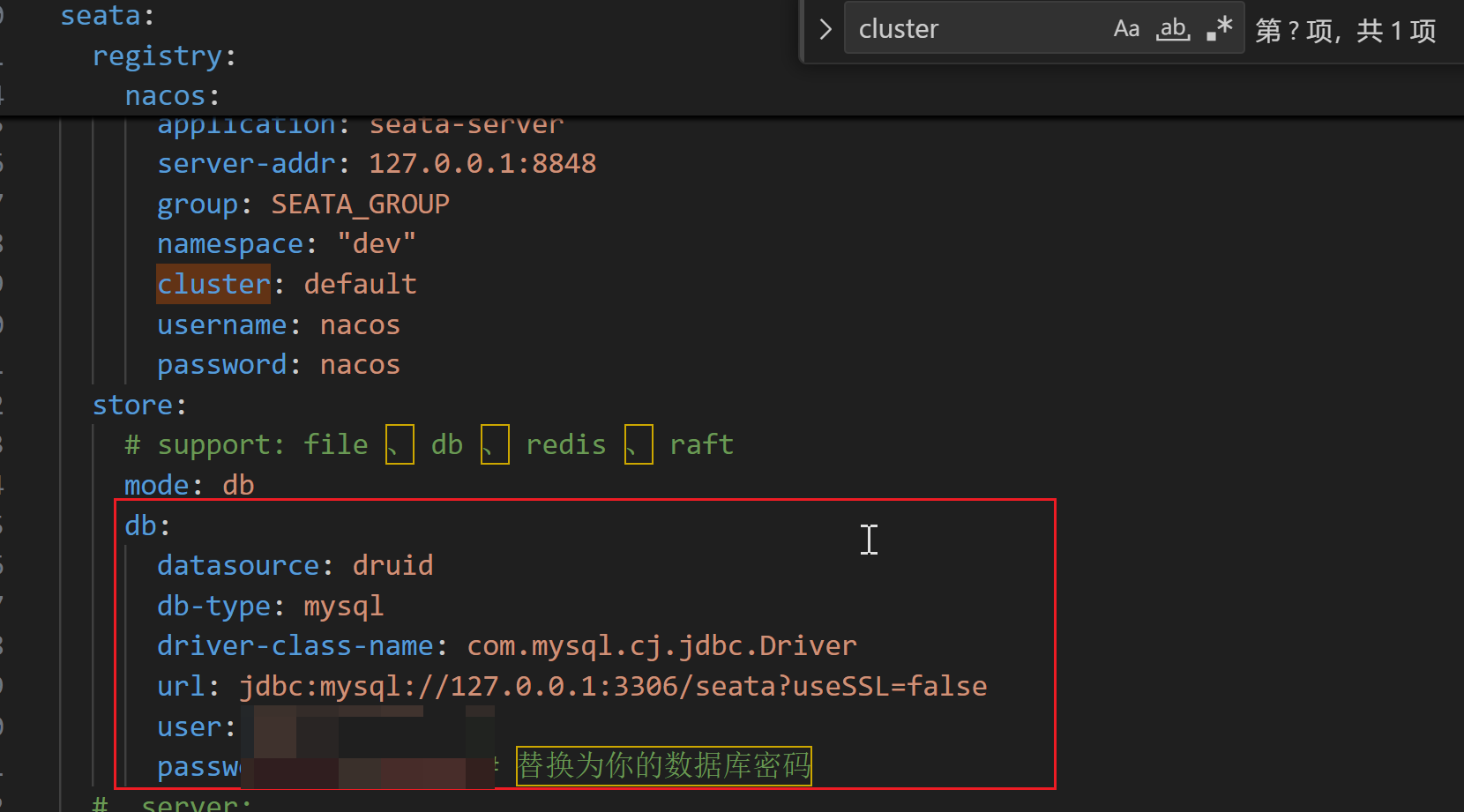
上面可以看到,连接了数据库,我们需要手动创建一个seata数据库。然后在里面执行如下语句:
--
-- Licensed to the Apache Software Foundation (ASF) under one or more
-- contributor license agreements. See the NOTICE file distributed with
-- this work for additional information regarding copyright ownership.
-- The ASF licenses this file to You under the Apache License, Version 2.0
-- (the "License"); you may not use this file except in compliance with
-- the License. You may obtain a copy of the License at
--
-- http://www.apache.org/licenses/LICENSE-2.0
--
-- Unless required by applicable law or agreed to in writing, software
-- distributed under the License is distributed on an "AS IS" BASIS,
-- WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-- See the License for the specific language governing permissions and
-- limitations under the License.
---- -------------------------------- The script used when storeMode is 'db' --------------------------------
-- the table to store GlobalSession data
CREATE TABLE IF NOT EXISTS `global_table`
(`xid` VARCHAR(128) NOT NULL,`transaction_id` BIGINT,`status` TINYINT NOT NULL,`application_id` VARCHAR(32),`transaction_service_group` VARCHAR(32),`transaction_name` VARCHAR(128),`timeout` INT,`begin_time` BIGINT,`application_data` VARCHAR(2000),`gmt_create` DATETIME,`gmt_modified` DATETIME,PRIMARY KEY (`xid`),KEY `idx_status_gmt_modified` (`status` , `gmt_modified`),KEY `idx_transaction_id` (`transaction_id`)
) ENGINE = InnoDBDEFAULT CHARSET = utf8mb4;-- the table to store BranchSession data
CREATE TABLE IF NOT EXISTS `branch_table`
(`branch_id` BIGINT NOT NULL,`xid` VARCHAR(128) NOT NULL,`transaction_id` BIGINT,`resource_group_id` VARCHAR(32),`resource_id` VARCHAR(256),`branch_type` VARCHAR(8),`status` TINYINT,`client_id` VARCHAR(64),`application_data` VARCHAR(2000),`gmt_create` DATETIME(6),`gmt_modified` DATETIME(6),PRIMARY KEY (`branch_id`),KEY `idx_xid` (`xid`)
) ENGINE = InnoDBDEFAULT CHARSET = utf8mb4;-- the table to store lock data
CREATE TABLE IF NOT EXISTS `lock_table`
(`row_key` VARCHAR(128) NOT NULL,`xid` VARCHAR(128),`transaction_id` BIGINT,`branch_id` BIGINT NOT NULL,`resource_id` VARCHAR(256),`table_name` VARCHAR(32),`pk` VARCHAR(36),`status` TINYINT NOT NULL DEFAULT '0' COMMENT '0:locked ,1:rollbacking',`gmt_create` DATETIME,`gmt_modified` DATETIME,PRIMARY KEY (`row_key`),KEY `idx_status` (`status`),KEY `idx_branch_id` (`branch_id`),KEY `idx_xid` (`xid`)
) ENGINE = InnoDBDEFAULT CHARSET = utf8mb4;CREATE TABLE IF NOT EXISTS `distributed_lock`
(`lock_key` CHAR(20) NOT NULL,`lock_value` VARCHAR(20) NOT NULL,`expire` BIGINT,primary key (`lock_key`)
) ENGINE = InnoDBDEFAULT CHARSET = utf8mb4;INSERT INTO `distributed_lock` (lock_key, lock_value, expire) VALUES ('AsyncCommitting', ' ', 0);
INSERT INTO `distributed_lock` (lock_key, lock_value, expire) VALUES ('RetryCommitting', ' ', 0);
INSERT INTO `distributed_lock` (lock_key, lock_value, expire) VALUES ('RetryRollbacking', ' ', 0);
INSERT INTO `distributed_lock` (lock_key, lock_value, expire) VALUES ('TxTimeoutCheck', ' ', 0);
同时改下微服务实例的application.yml
spring:profiles:include: feignactive: devapplication:name: seata-accountdatasource:driver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://localhost:3306/account_tbl?useUnicode=true&characterEncoding=utf-8&useSSL=falseusername: xxxxpassword: yyyycloud:nacos:server-addr: 127.0.0.1:8848config:import-check:enabled: falsenamespace: ${spring.profiles.active:dev}discovery:namespace: ${spring.profiles.active:dev}
server:port: 10000
mybatis-plus:mapper-locations: classpath*:/mapper/**/*.xmlconfiguration:map-underscore-to-camel-case: true # 驼峰映射(建议开启)
seata:tx-service-group: default_tx_group # 显式设置事务组名称registry:type: nacosnacos:server-addr: 127.0.0.1:8848group: SEATA_GROUPapplication: seata-server # 与 Server 端一致namespace: ${spring.profiles.active:dev}config:type: nacosnacos:server-addr: 127.0.0.1:8848group: SEATA_GROUPdata-id: seataServer.propertiesnamespace: ${spring.profiles.active:dev}# 事务组映射(必须配置!)service:vgroup-mapping:default_tx_group: default # 事务组名需与Seata Server的配置一致
---
spring:config:import:- nacos:common.properties?group=order- nacos:database.properties?group=orderactivate:on-profile: dev
---
spring:config:import:- nacos:common.properties?group=order- nacos:database.properties?group=orderactivate:on-profile: test
---
spring:config:import:- nacos:common.properties?group=order- nacos:database.properties?group=orderactivate:on-profile: prod
然后我们在nacos里面配置下properties:
| seataServer.properties |
SEATA_GROUP
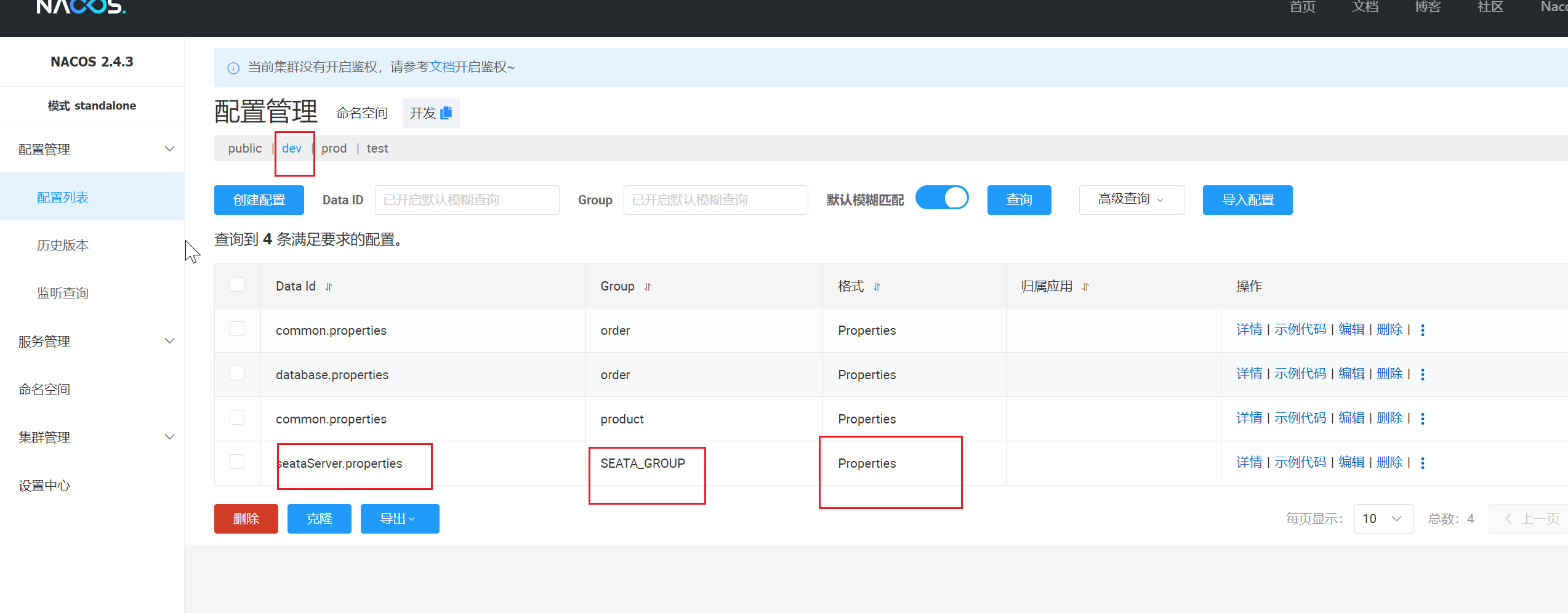
properties里面内容如下:记得改下账号和密码:
# 事务组映射
service.vgroupMapping.default_tx_group=default# 存储模式(DB 高可用)
store.mode=db
store.db.datasource=druid
store.db.dbType=mysql
store.db.driverClassName=com.mysql.cj.jdbc.Driver
store.db.url=jdbc:mysql://127.0.0.1:3306/seata?useSSL=false
store.db.user=xxxx
store.db.password=yyyy然后我们启动nacos,再启动seata,最后启动微服务。记得4个微服务都要改下yml文件。
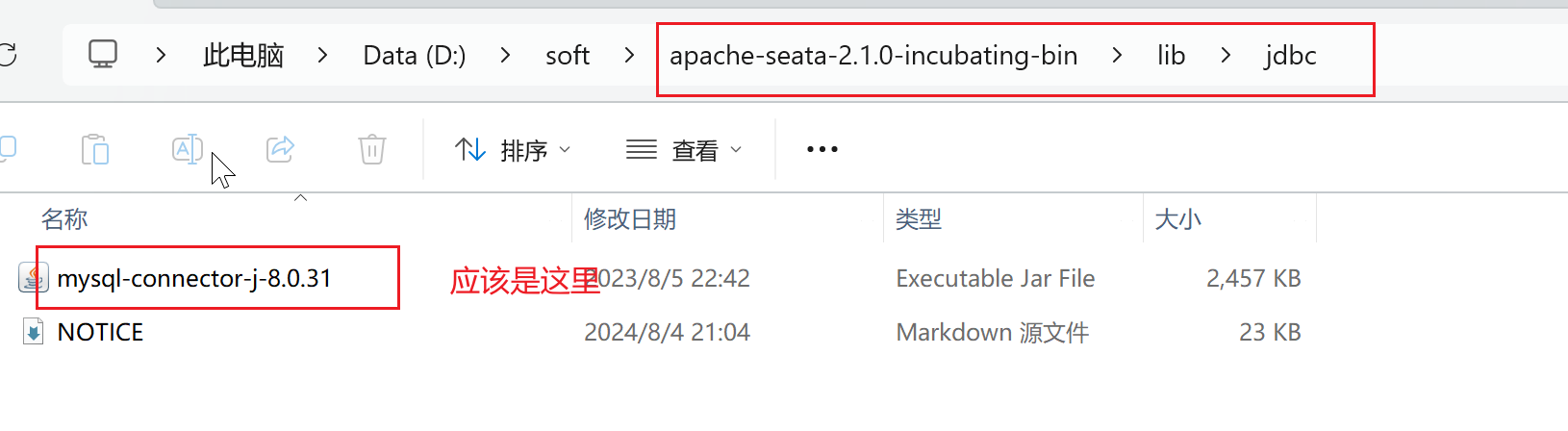
(如果启动seata报错找不到mysql的jar包,按照错误提示,把这个jar包放在它提示的路径下就可以。如下图所示:
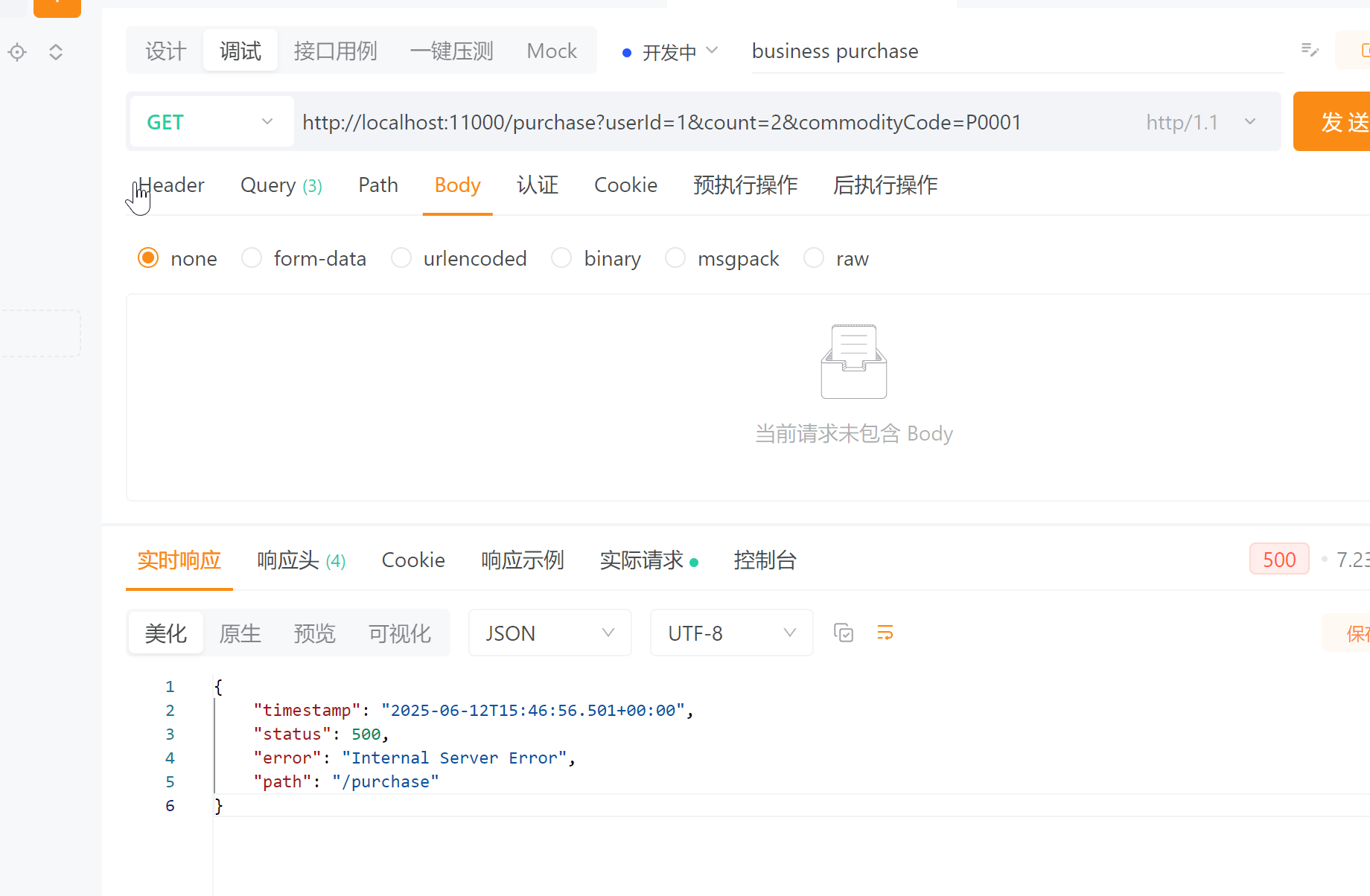
下面我们来验证下,全局事务有没有生效。
http://localhost:11000/purchase?userId=1&count=2&commodityCode=P0001
apipost调用如上接口,可以看到报错了。然后查看数据库:
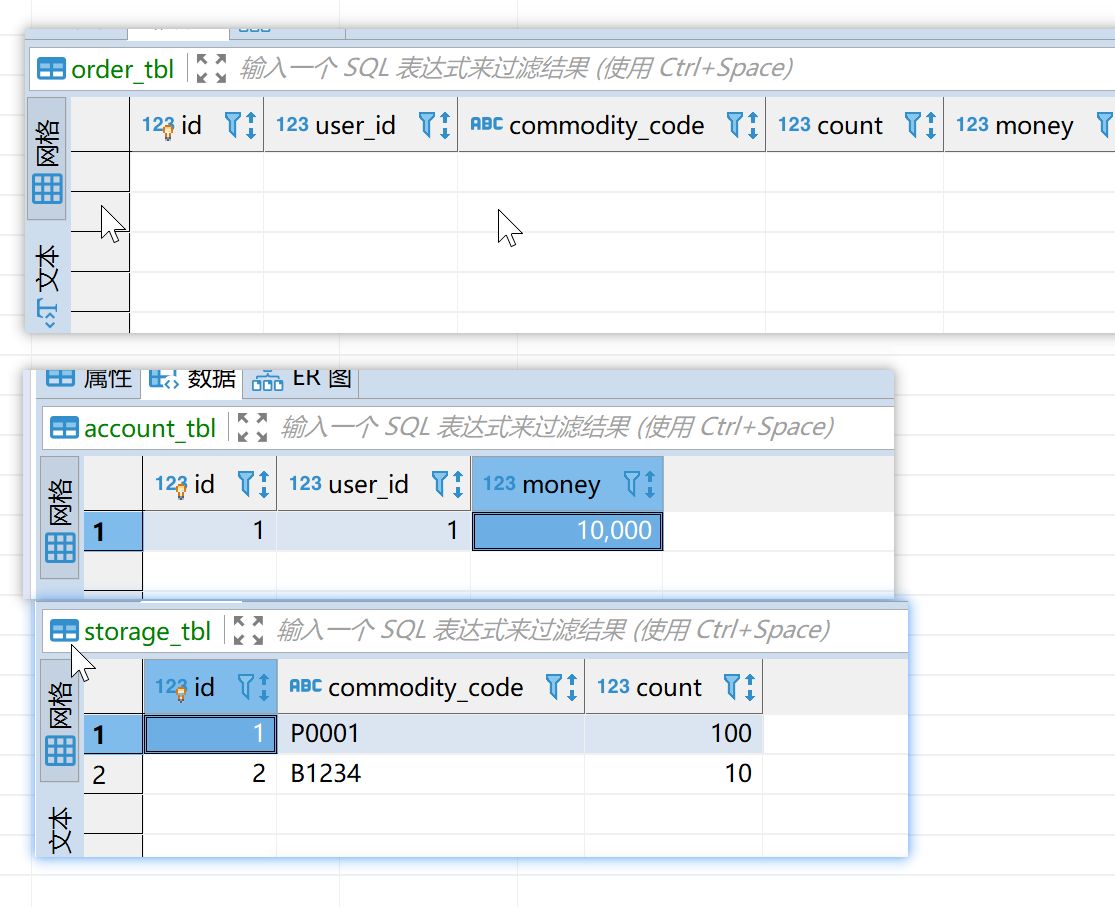 如上图,我们可以看到订单数据回滚(没有生成)。库存100(没有变动)金额10000(没有变动)
如上图,我们可以看到订单数据回滚(没有生成)。库存100(没有变动)金额10000(没有变动)
以上是seata集成nacos的一个简单示例。更复杂的还有建立seata集群,大家可以研究下。特别推荐AI工具学习,比如豆包,deepseek等。查找效率很高,帮助很大。