个人网站备案网站名称聚合广告联盟
目录
前言
1. isTerminated()方法
2. awaitTermination()方法
3.getTaskCount()方法和executor.getCompletedTaskCount()方法结合使用
4.使用CountDownlatch类
前言
通常我们使用线程池的时候,系统处于运行的状态,而线程池本身就是主要为了线程复用,需要线程池跟随系统一直跑起来。
大多数时候,对于我们来说线程池就是一个黑盒,纵然我们可能对线程池的实现,底层原理盘的比老核桃还圆润,但是对于线程池的异常处理、事务处理、上下文传递、以及如何判断线程池中的任务执行状态,我们仍然是不可言状的。无法掌控、无法预测,会在一些细微时候给我们的应用程序带来致命一击。
那么我来聊下以下几种判断线程池中任务是否执行完毕的方式,谁赞成,谁反对。
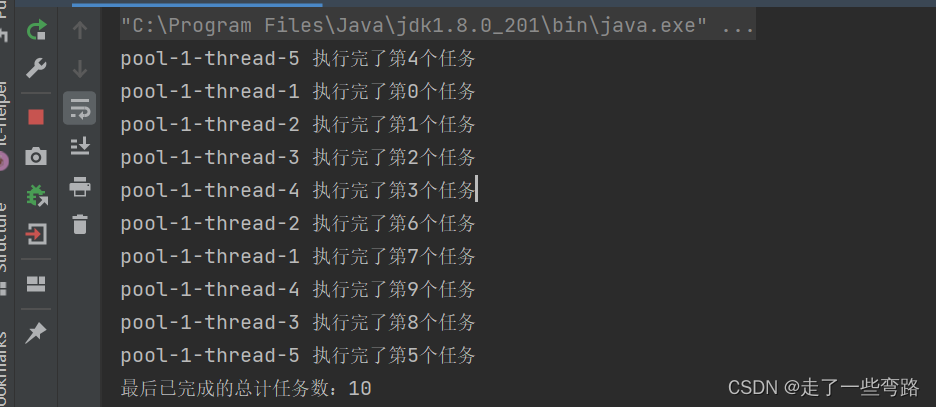
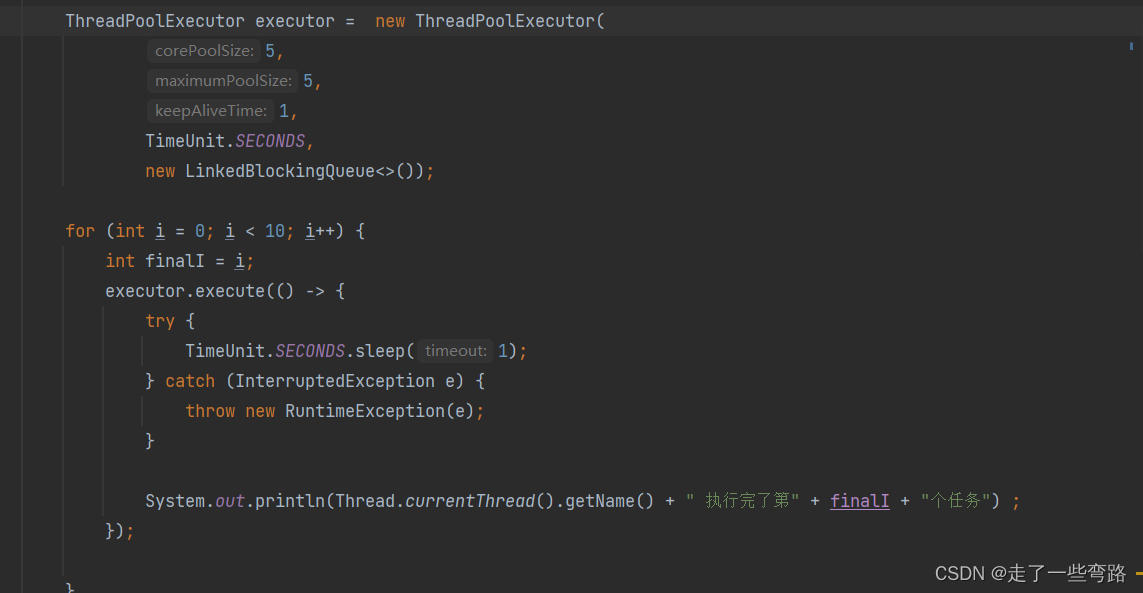
我们先把线程池启动起来,线程数5个,往线程池中提交10个任务。
基于上面的线程池,开始表演。
1. isTerminated()方法
通过终止线程池 判断线程池中是否终止 来判断任务是否执行完毕 但是一般线程池也不会终止,不推荐使用。
但是,有些个别情况我们确实需要停止线程池,比如系统停止的时候,异常终止的时候,如何优雅的停止线程池不得不来考虑下,在高负荷的系统中,停止线程池好似那狂奔180迈的迈巴赫踩下刹车,能安全平稳的停下来最好不过了。
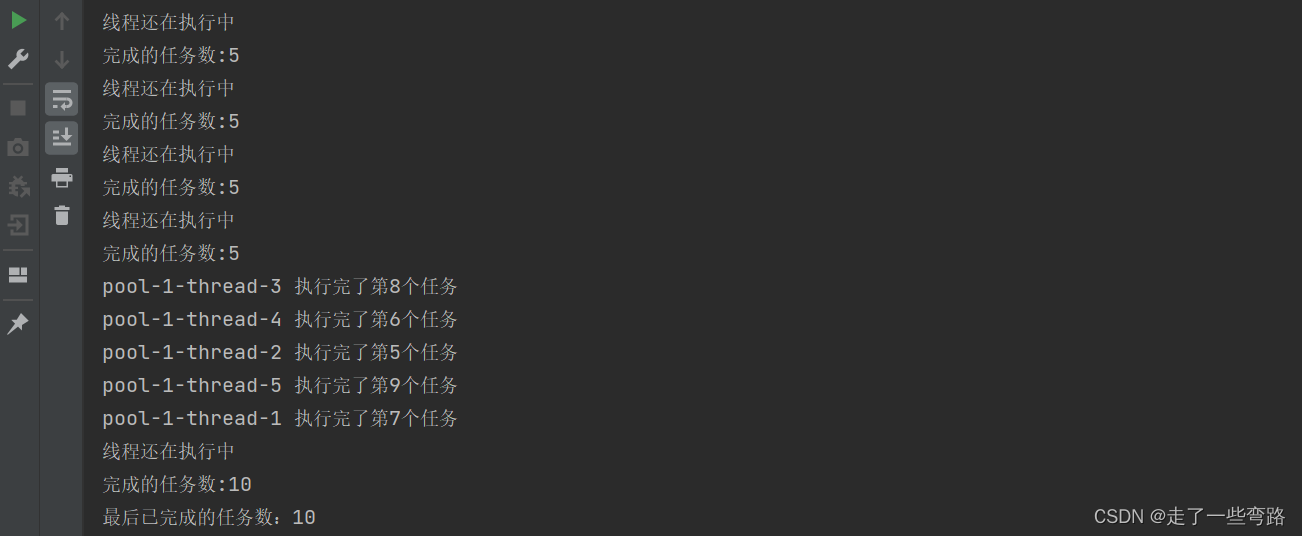
//终止线程池executor.shutdown();while (!executor.isTerminated()) {try {TimeUnit.MILLISECONDS.sleep(100);} catch (InterruptedException e) {throw new RuntimeException(e);}System.out.println("线程还在执行中");long taskCount = executor.getCompletedTaskCount();System.out.println("完成的任务数:" + taskCount);}执行结果如下,完成任务数10
 2. awaitTermination()方法
2. awaitTermination()方法
使用awaitTermination()方法会阻塞当前线程,等待线程池执行任务,但是呢这个等待的时间是不确定,好似等待约会的女孩化妆,耗时不固定,但等待时间要足够长,缺点就是不可控,不可预测,正如我们的人生一样,茫茫无边际。
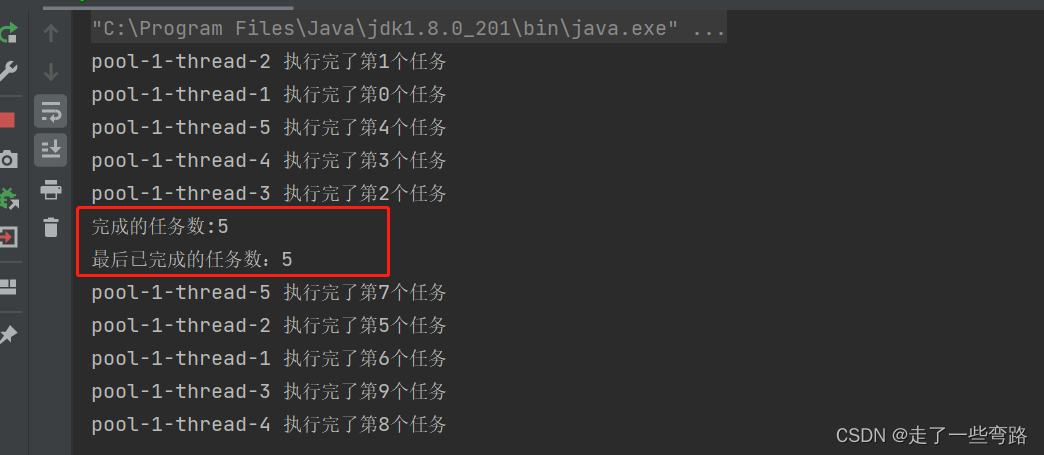
如果等待时间足够长,输出是没问题的
try {executor.awaitTermination(10, TimeUnit.SECONDS);long taskCount = executor.getCompletedTaskCount();System.out.println("完成的任务数:" + taskCount);} catch (InterruptedException e) {e.printStackTrace();} 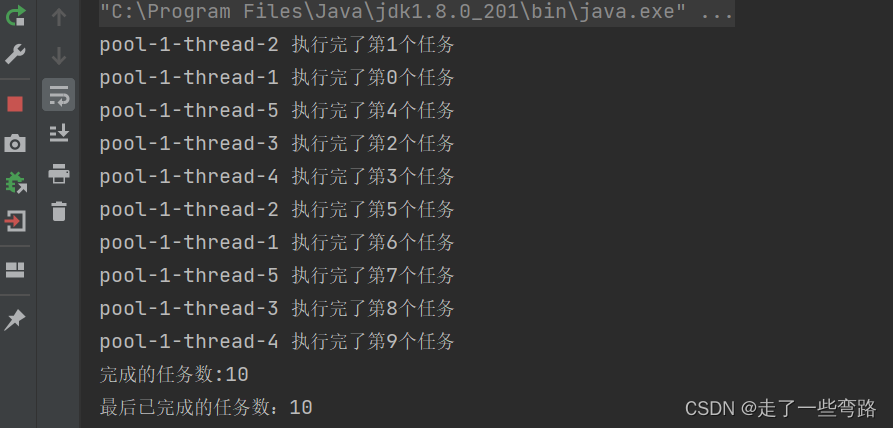
但如果恰好配置的时间不够,我们给配置成1s,就像恋爱时追女孩子的耐心不够,不好意思,你等不完她的化妆时间,注定孤独一生,自然也完成不了所有的任务
可以看到我们在获取任务完成个数的时候只有5条。 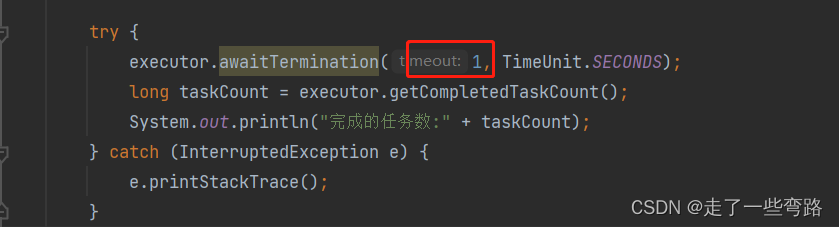
3. getTaskCount()方法和executor.getCompletedTaskCount()方法结合使用
while (executor.getTaskCount() != executor.getCompletedTaskCount()) {System.out.println("所有任务数:" + executor.getTaskCount() + ";已完成任务数" + executor.getCompletedTaskCount());}System.out.println("最后已完成的任务数:" + executor.getCompletedTaskCount());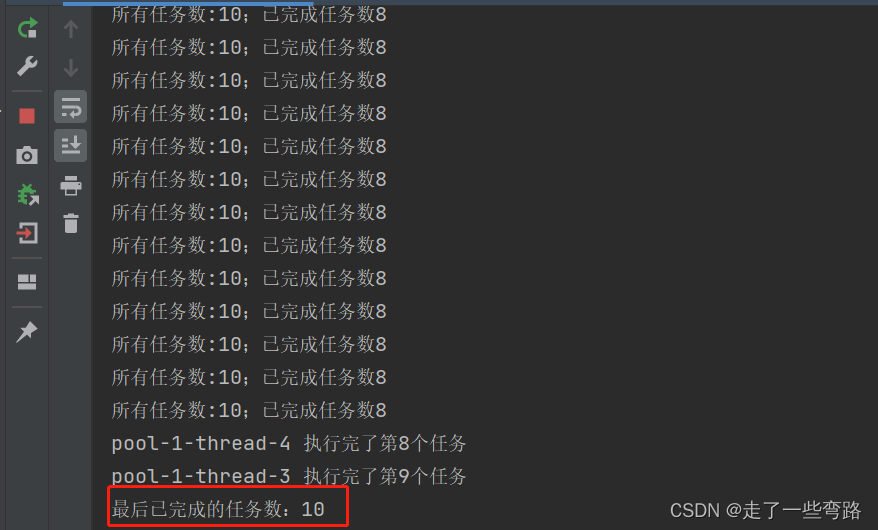
4. 使用CountDownlatch类
很多时候线程池并不专一,喜欢脚踏多个业务船,可能提交多种业务数据,我们只想看到我们提交的业务数据执行情况。
比如下面,我们再提交15条任务给线程池,线程池这家伙可是来着不拒的。
//在业务线程池正在执行上面10条任务的时候,再新提交15条任务,而我们只关注这15条任务该怎么做呢for (int i = 0; i < 15; i++) {int finalI = i;executor.execute(() -> {try {TimeUnit.SECONDS.sleep(1);} catch (InterruptedException e) {throw new RuntimeException(e);}System.out.println("【新提交的任务】" + Thread.currentThread().getName() + " 执行完了第" + finalI + "个任务") ;});}这个时候我们就可以请求外援,使用CountDownlatch来进行上述代码的改造,通过countDown()方法进行计数,await()方法阻塞等待,对完成的任务进行判断。
CountDownLatch latch = new CountDownLatch(15);for (int i = 0; i < 15; i++) {int finalI = i;executor.execute(() -> {try {TimeUnit.SECONDS.sleep(1);} catch (InterruptedException e) {throw new RuntimeException(e);}System.out.println("【新提交的任务】" + Thread.currentThread().getName() + " 执行完了第" + finalI + "个任务") ;latch.countDown();});}latch.await();System.out.println("新提交的任务执行完成啦");System.out.println("最后已完成的总计任务数:" + executor.getCompletedTaskCount());5. 手动维护一个线程安全的计数器
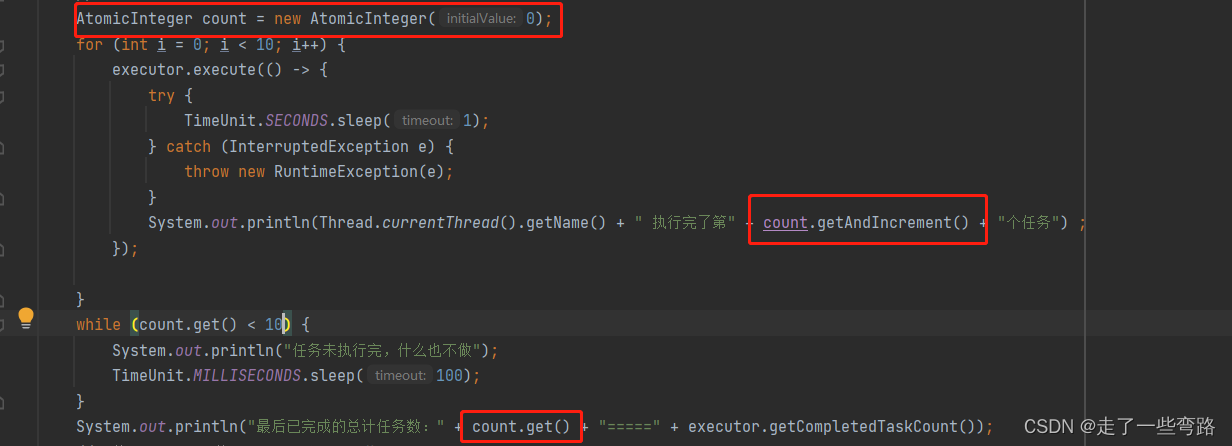
比如说JUC包下常见的基于CAS的AtomicInteger类,基于底层的unsafe类,在多线程的情况下依然可以保证线程的安全,我们可以放心的将它在线程池中进行累加,直到累加到和提交的任务数量一致,线程池也就执行完了所有的任务。
6. 使用Future
我们也可以换个路子,提交线程池不适用execute()方法,使用submit()方法,记得使用submit()方法要谨慎些,具体的坑可以参考之前的文章【线程池】换个姿势来看线程池中不一样的阻塞队列(一)_走了一些弯路的博客-CSDN博客