php网站制作实例教程下载百度免费版
目录
一、题目引入
二、举出回溯例子进行分析
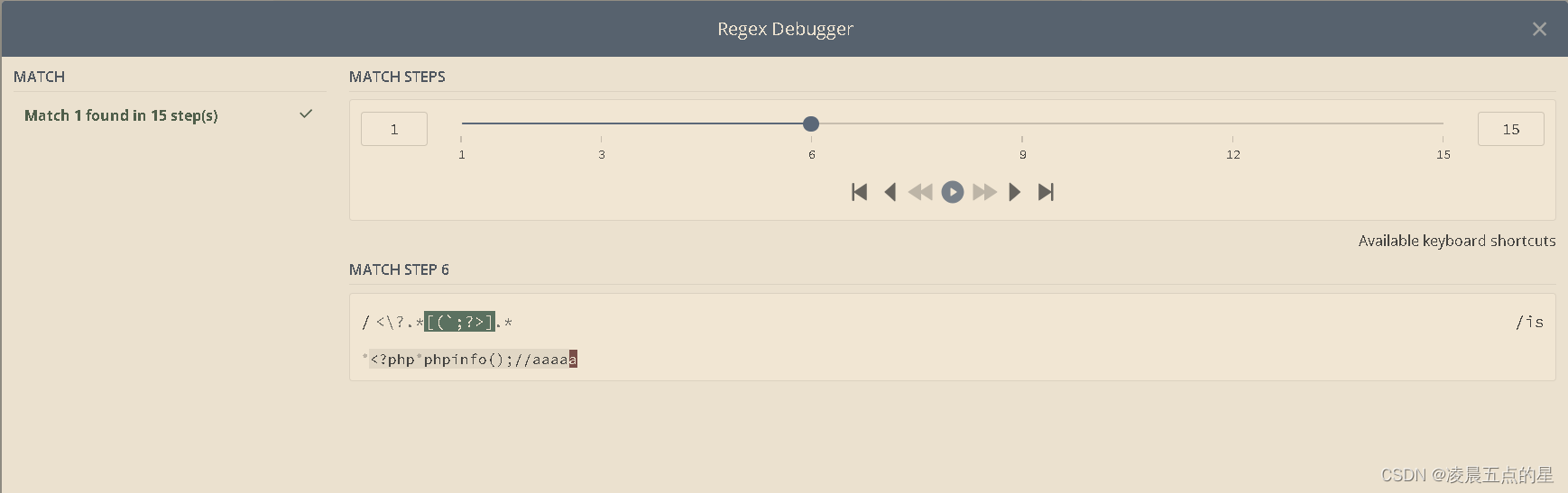
第一步: 正则往前匹配
第二步:匹配到头
第三步:往回匹配
第四步:直到分号结束 (匹配上)
原因:
三、进入正题一(分析题型)
四、进入正题二(分析题型)
一、题目引入
PHP利用PCRE回溯次数限制绕过某些安全限制,大意是判断一下用户输入的内容有没有 PHP 代码,如果没有,则写入文件
<?php
function is_php($data){ return preg_match('/<\?.*[(`;?>].*/is', $data);
}
<?php eval()if(!is_php($input)) {// fwrite($f, $input); ...
}二、举出回溯例子进行分析
<\?.*[(`;?>].*第一步: 正则往前匹配

第二步:匹配到头
第三步:往回匹配

第四步:直到分号结束 (匹配上)

原因:
PHP 为了防止正则表达式的拒绝服务攻击(reDOS),给 pcre 设定了一个回溯次数上限 pcre.backtrack_limit。(100万次)
三、进入正题一(分析题型)
PHP文件如下所示:
<?php
// greeting[]=Merry Christmas&greeting[]=123
function areyouok($greeting){return preg_match('/Merry.*Christmas/is',$greeting); //正则匹配
}
// greeting[]=123
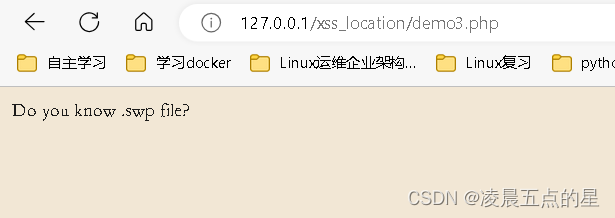
// $greeting=@$_POST['greeting'];if(!areyouok($greeting)){// NULL != false// Null !== false// null !== false// strposif(strpos($greeting,'Merry Christmas') !== false){ //字符查找,如果查找到返回字符的位置,没有就返回falseecho 'welcome to nanhang. '.'flag{i_Lov3_NanHang_everyThing}';}else{echo 'Do you know .swp file?';}
}else{echo 'Do you know PHP?';
}
解析:strpos:判断字符串位置,str:字符串,position判断字符串位置
在分析代码的时候我们陷入了有和不有的矛盾
这是我们会陷入走不进if的矛盾中,有人便会提出那我匹配为greeting=Merry Christmas不就可以了,而结果却是第一个if都无法进入
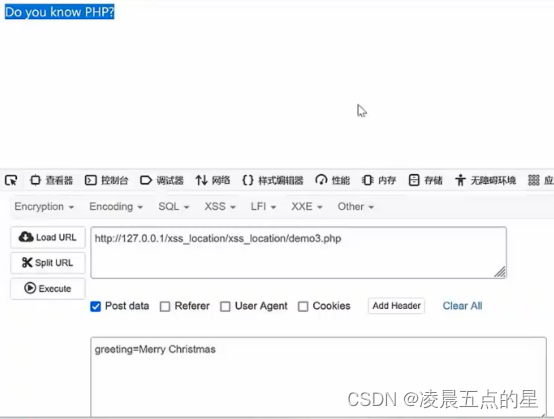
经过思考,我们传入一个数组,而这样我们就拿下了,那么我们就要思考这个数组有什么含义
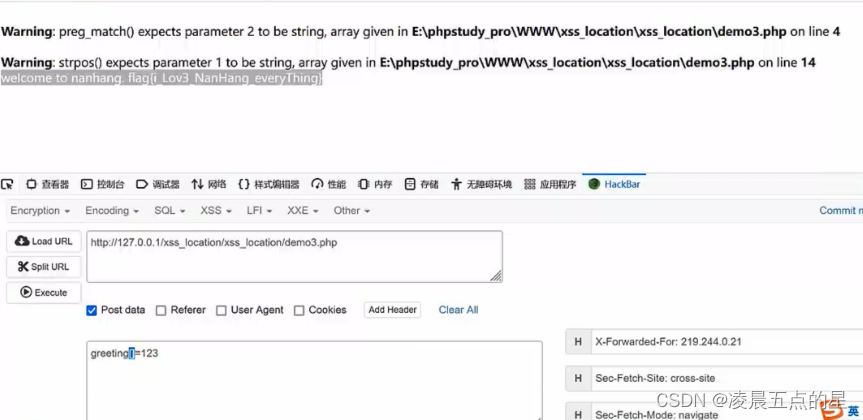
分析:strpos它是用来对比字符串的,而我们传入了一个数组,这个时候传入的数值就会变为NULL,进而与我们的false比较,只有为真才会继续往下传

pass:(!==false)中一个等号和两个等号的区别,一个等号不是严格的比对,在数值类型下为弱类型转换都可以转换为0,两个等号没有弱类型转换,是严格不相等因此会继续匹配
四、进入正题二(分析题型)
<?php
// 利用回溯绕过正则表达式
//正则匹配有次数限制 他怕dos攻击
// 100万次 回溯
// var_dump(ini_get('pcre.backtrack_limit'));
// greeting[]=Merry Christmas&greeting[]=123
// var_dump(ini_get('pcre.backtrack_limit'));
// var_dump(strpos(['aaaa'],'Merry Christmas'));
// var_dump(NULL !== false);
function areyouok($greeting){return preg_match('/Merry.*Christmas/is',$greeting);
}// 回溯的问题
$greeting=@$_POST['greeting'];
if(!is_array($greeting)){if(!areyouok($greeting)){// strpos string postionif(strpos($greeting,'Merry Christmas') !== false){echo 'Merry Christmas. '.'flag{i_Lov3_NanHang_everyThing}';}else{echo 'Do you know .swp file?';}}else{echo 'Do you know PHP?';}
} else {echo 'fuck array!!!';
}
?>
此段代码升级,给代码中加入了判断if(!is_array($greeting)),会先判断数组,此时我们就该去烤炉回溯的问题
思路:输入一个字符串后面跟上一百万个字符,因为回溯限制的问题,匹配一百万次后,就会传入参数,匹配前面的字符串,而前面是有字符串的,那么就为Ture,那么就能传入成功