专业做曝光引流网站搜索网页内容
一:镜头
1.1MP的概念
相机中MP的意思是指百万像素。MP是mega pixel的缩写。mega意为一百万,mega pixel 指意为100万像素。“像素”是相机感光器件上的感光最小单位。就像是光学相机的感光胶片的银粒一样,记忆在数码相机的“胶片”(存储卡)上的感光点就是像素;
要想得到分辨率高(也就是细腻的照片),就必须保证有一定的像素数。当然并不是像素数越大,照片的就越清晰,照片的清晰度是由“点像"决定,而并非像素数,像素数是有效像素的总和,点像素是每点(寸等)有多少像素。
1.2 靶面尺寸
该参数即感光元件的面积大小,值越大表明面积越大,面积越大进光量就越大,信噪比
自然会相应提高,对于暗光环境会有更好的成像效果。
相机的靶面尺寸

镜头的靶面尺寸

1.3焦距
不同焦距所看到的距离和角度不同
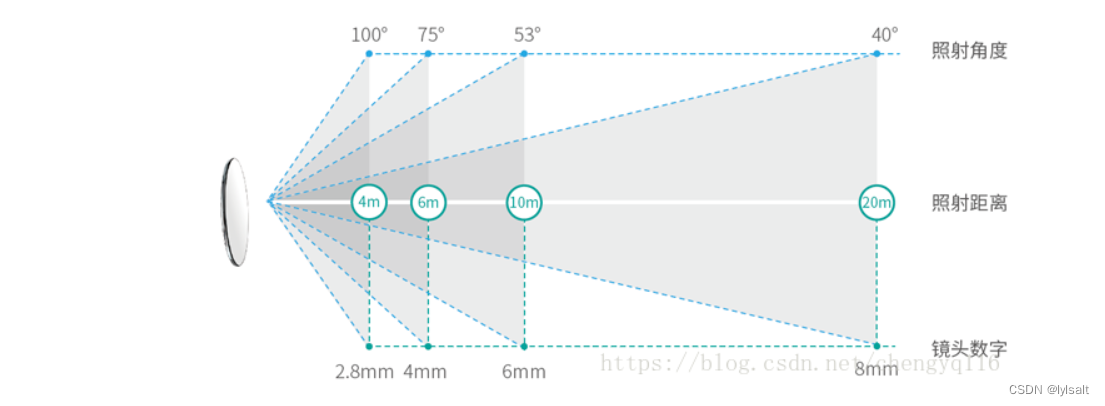
焦距6mm,视场角45度,焦距适中,经测试,在该相机下,最远可以识别11m处的装甲板,稳定识别水平距离9M内的装甲板。
二:相机
2.1宽容度/动态范围
动态范围即感光元件能够记录的光强从最低到最高亮度的范围。最低即感光元件刚好有输出( 或是当没有任何光线进入时产生的响应,即暗电流) ,会根据光线变化而产生电荷变化的 阈值 ;最高亮度范围则是相机能够捕捉的最大累积光强,就像放大器一样,超过了其输出上限就会产生截断 ,此时即使继续提高曝光时间或外界光强增大,转换原件的输出也不会变得更大。相机的画面很暗,但是灯条中间仍然发白,问题在于相机的宽容度不足上。选购相机的时候应该选择动态范围大的相机。