啥是东莞网站制作公司微信小程序开发费用一览表
Spring学习笔记(2)
- 一、Spring配置非定义Bean
- 1.1 DruidDataSource
- 1.2、Connection
- 1.3、Date
- 1.4、SqlSessionFactory
- 二、Bean实例化的基本流程
- 2.1 BeanDefinition
- 2.2 单例池和流程总结
- 三、Spring的bean工厂后处理器
- 3.1 bean工厂后处理器入门
- 3.2、注册BeanDefinition
- 3.3、BeanDefinitionRegistryPostProcessor
- 3.4 完善实例化流程图
- 3.5、自定义@Component
- 四、Spring的Bean后处理器
- 4.1 概念和入门
- 4.2 当中的一些调用方法的顺序
- 4.3 更加详细的实例化基本操作
- 五、Spring的生命周期
- 5.1 概述
- 5.2 初始化阶段执行的步骤
- 5.3 初始化阶段注入属性信息封装
- 5.4、属性注入的三种情况
- 5.4.1 单项注入的代码验证
- 5.4.2 循环依赖概念及解决方案
- 5.4.3 三级缓存的设计原理
- 5.5 循环依赖源码流程剖析
- 5.6 Aware接口
- 六、IoC容器实例化Bean完整流程图展示
- 七、Spring xml方式整和第三方框架
- 7.1 Mybatis整合Spring实现
- 7.2、MyBatis整合Spring源码解析
- 7.3 加载外部properties文件
- 7.4、自定义空间步骤
一、Spring配置非定义Bean
以上在xml中配置的Bean都是自己定义的,例如: UserDaolmpl,UserServicelmpl。但是,在实际开发中有些功能类并不是我们自己定义的,而是使用的第三方jar包中的,那么,这些Bean要想让Spring进行管理,也需要对其进行配置
- 配置非自定义的Bean需要考虑如下两个问题:
- 被配置的Bean的实例化方式是什么?无参构造、有参构造、静态工厂方式还是实例化工厂方式;
- 被配置的Bean是否需要注入必要属性
1.1 DruidDataSource
配置Druid数据源交由Spring管理
导入Druid坐标
<!--mysql驱动-->
<dependency><groupId>mysql</groupid><artifactId>mysql-connector-java</artifactId><version>5.1.49</version>
</dependency>
<!-- druid数据源-->
<dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><version>1.1.23</version>
</dependency>
配置文件xml
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource"><property name="driverClassName" value="com.mysql.cj.jdbc.Driver"></property><property name="url" value="jdbc:mysql://localhost:3306/mybatis"></property><property name="username" value="root"></property><property name="password" value="123456"></property>
</bean>
1.2、Connection
Connection的产生是通过DriverManager的静态方法getConnection获取的,所以我们要用静态工厂方式配置
<bean class="java.lang.class" factory-method="forName"><constructor-arg name="className" value="com.mysql.jdbc.Driver" />
</bean>
<bean id="connection" class="java.sql.DriverManager" factory-method="getConnection" scope="prototype"><constructor-arg name="url" value="jdbc:mysql:///mybatis" /><constructor-arg name="user" value="root"/><constructor-arg name="password" value="123456"/>
</bean>
1.3、Date
产生一个指定日期格式的对象,原始代码如下
String currentTimeStr = "2023-08-27 07:20:00" ;
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
Date date = simpleDateFormat.parse(currentTimeStr);
可以看成是实例工厂方式,使用Spring配置方式产生Date实例
<bean id="simpleDateFormat" class="java.text.SimpleDateFormat"><constructor-arg name="pattern" value="yyyy-MM-dd HH:mm:ss" />
</bean>
<bean id="date" factory-bean="simpleDateFormat" factory-method="parse"><constructor-arg name="source" value="2023-08-27 07:20:00"/>
</bean>
1.4、SqlSessionFactory
配置SqlSessionFactory交由Spring管理
导入Mybatis相关坐标
<dependency><groupId>org.mybatis</groupId><artifactId>mybatis</artifactId><version>3.5.10</version>
</dependency>
<dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.30</version>
</dependency>
<!--静态工厂方法-->
<bean id="inputStream" class="org.apache.ibatis.io.Resources" factory-method="getResourceAsStream"><constructor-arg name="resource" value="mybatis-config.xml"></constructor-arg>
</bean>
<!--无参构造实例化-->
<bean id="builder" class="org.apache.ibatis.session.SqlSessionFactoryBuilder"></bean>
<!--实例化工厂-->
<bean id="factory" factory-bean="builder" factory-method="build"><constructor-arg name="inputStream" ref="inputStream"></constructor-arg>
</bean>
二、Bean实例化的基本流程
2.1 BeanDefinition
- Spring容器在进行初始化的时候,会将xml配置的
<bean>信息封装成一个BeanDefinition对象 - 所有的BeanDefinition对象会集中存储在
BeanDefinitionMap集合当中 - Spring框架会调用读取器读取BeanDdfinitionMap当中的每一个信息,通过反射创建出bean对象,然后再进行初始化操作,最后将所有的数据全部存储到
singletonObjects集合当中 - 最后通过
getBean方法在singletonObjects集合当中找到创建的Bean对象

DefaultListableBeanFactory对象内部维护着一个Map用于存储封装好的BeanDefinitionMap
public class DefaultListableBeanFactory extends ... implements ... {//存储<bean>标签对应的BeanDefinition对象//key:是Bean的beanName,value:是Bean定义对象BeanDefinitionprivate final Map<String,BeanDefinition> beanDefinitionMap;
}
Spring框架会取出beanDefinitionMap中的每个BeanDefinition信息,反射构造方法或调用指定的工厂方法生成Bean实例对象,所以只要将BeanDefinition注册到beanDefinitionMap这个Map中,Spring就会进行对应的Bean的实例化操作
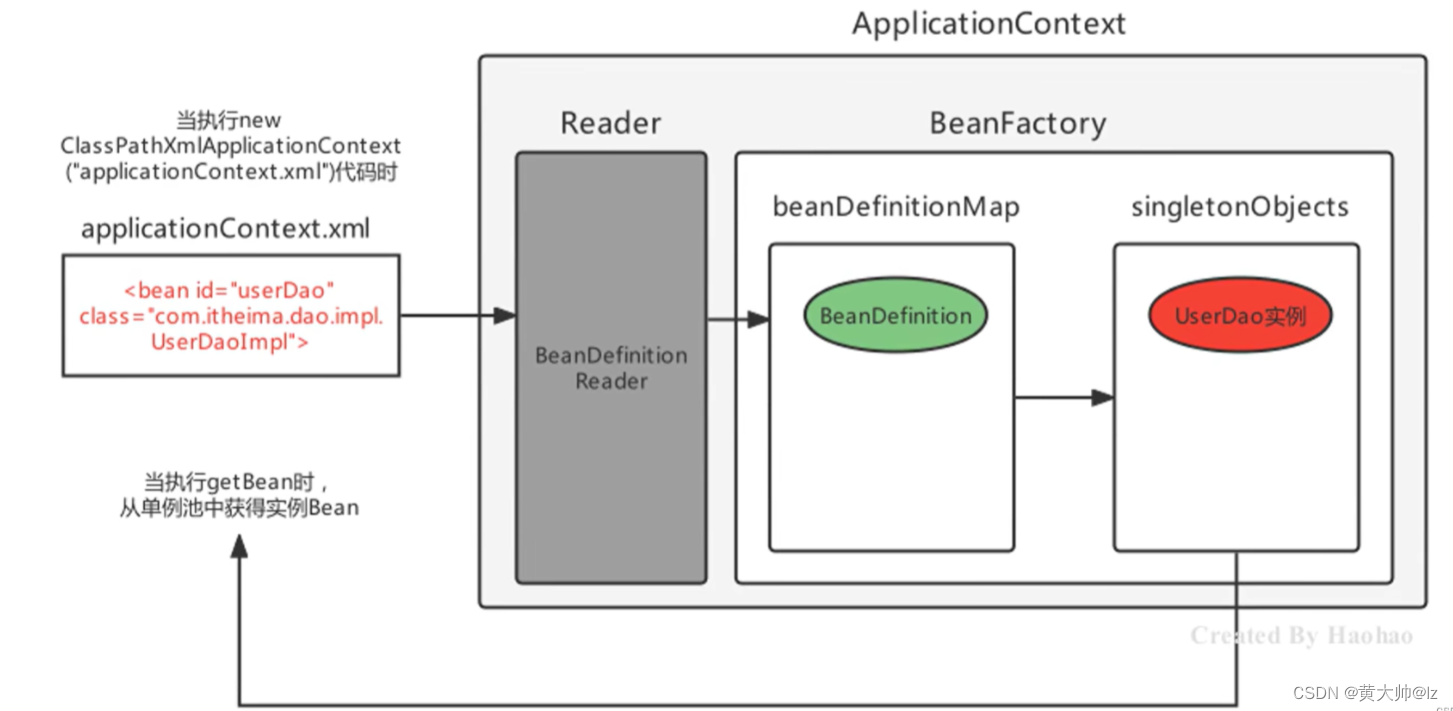
2.2 单例池和流程总结
基本流程:
- 加载xml配置文件,解析获取配置中的每个
<bean>的信息,封装成一个个的BeanDefinition对象; - 将BeanDefinition存储在一个名为
beanDefinitionMap的Map<String,BeanDefinition>中; - ApplicationContext底层遍历
beanDefinitionMap,创建Bean实例对象; - 创建好的Bean实例对象,被存储到一个名为singletonObjects的
Map<String,Object>中; - 当执行applicationContext.getBean(beanName)时,从
singletonObjects去匹配Bean实例返回。
三、Spring的bean工厂后处理器
3.1 bean工厂后处理器入门
Spring的后处理器是Spring对外开发的重要扩展点,允许我们介入到Bean的整个实例化流程中来,以达到动态注册BeanDefinition,动态修改BeanDefinition,以及动态修改Bean的作用。
- Spring主要有两种后处理器:
BeanFactoryPostProcessor: Bean工厂后处理器,在BeanDefinitionMap填充完毕,Bean实例化之前执行;BeanPostProcessor: Bean后处理器,一般在Bean实例化之后,填充到单例池singletonObjects之前执行。
Bean工厂后处理器-BeanFactoryPostProcessor
BeanFactoryPostProcessor是一个接口规范,实现了该接口的类只要交由Spring容器管理的话,那么Spring就会回调该接口的方法,用于对BeanDefinition注册和修改的功能。
BeanFactoryPostProcessor定义如下:
public interface BeanFactoryPostProcessor {void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory);
}
3.2、注册BeanDefinition
使用这种方法,可以不用再spring容器内在创建一个类的<bean>标签
public class MyBeanFactoryProcessor implements BeanFactoryPostProcessor {@Overridepublic void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException {System.out.println("beandefinitionMap填充完毕后回调该方法");//1.注册一个beandefinition 创建一个RootBeanDefinition()对象RootBeanDefinition rootBeanDefinition = new RootBeanDefinition();rootBeanDefinition.setBeanClassName("com.huanglei.Dao.Impl.processorImpl");//2.将beanFactory强转成DefaultListableBeanFactory类型DefaultListableBeanFactory beanFactory1 = (DefaultListableBeanFactory) beanFactory;beanFactory1.registerBeanDefinition("processor",rootBeanDefinition);}
}
@Test
public void demo2(){ClassPathXmlApplicationContext classPathXmlApplicationContext = new ClassPathXmlApplicationContext("beans.xml");Object processor = classPathXmlApplicationContext.getBean("processor");System.out.println(processor);
}
3.3、BeanDefinitionRegistryPostProcessor
Spring提供了一个BeanFactoryPostProcessor的子接口BeanDefinitionRegistryPostProcessor专门用于注册BeanDefinition操作
public class MyBeanDefinitionRegistryPostProcessor implements BeanDefinitionRegistryPostProcessor {@Overridepublic void postProcessBeanDefinitionRegistry(BeanDefinitionRegistry beanDefinitionRegistry) throws BeansException {//创建一个RootBeanDefinition()对象RootBeanDefinition rootBeanDefinition = new RootBeanDefinition();rootBeanDefinition.setBeanClassName("com.huanglei.Dao.Impl.processorImpl");//不需要强转就可以创建一个BeanbeanDefinitionRegistry.registerBeanDefinition("personDao",rootBeanDefinition);}@Overridepublic void postProcessBeanFactory(ConfigurableListableBeanFactory configurableListableBeanFactory) throws BeansException {}
}
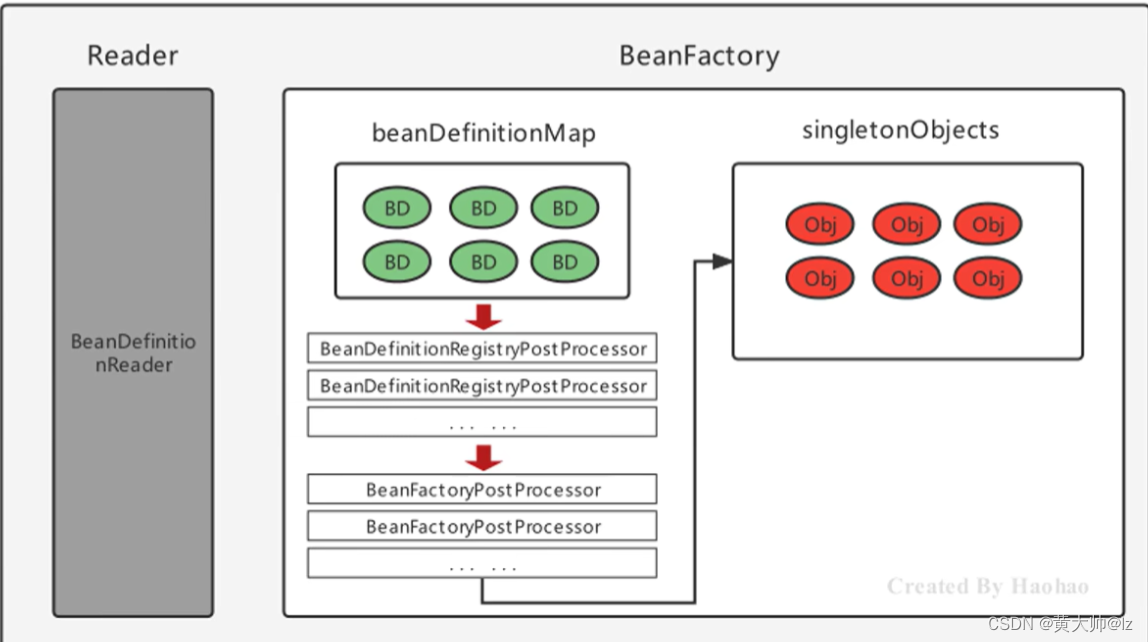
3.4 完善实例化流程图
BeanFactoryPostProcessor在SpringBean的实例化过程中的体现
3.5、自定义@Component
要求:
- 自定义@MyComponent注解,使用在类上;
- 使用资料中提供好的包扫描器工具BaseClassScanUtils完成指定包的类扫描;
- 自定义BeanFactoryPostProcessor完成注解@MyComponent的解析,解析后最终被Spring管理。
BaseClassScanUtils:
public class BaseClassScanUtils {//设置资源规则private static final String RESOURCE_PATTERN = "/**/*.class";public static Map<String, Class> scanMyComponentAnnotation(String basePackage) {//创建容器存储使用了指定注解的Bean字节码对象Map<String, Class> annotationClassMap = new HashMap<String, Class>();//spring工具类,可以获取指定路径下的全部类ResourcePatternResolver resourcePatternResolver = new PathMatchingResourcePatternResolver();try {String pattern = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX +ClassUtils.convertClassNameToResourcePath(basePackage) + RESOURCE_PATTERN;Resource[] resources = resourcePatternResolver.getResources(pattern);//MetadataReader 的工厂类MetadataReaderFactory refractory = new CachingMetadataReaderFactory(resourcePatternResolver);for (Resource resource : resources) {//用于读取类信息MetadataReader reader = refractory.getMetadataReader(resource);//扫描到的classString classname = reader.getClassMetadata().getClassName();Class<?> clazz = Class.forName(classname);//判断是否属于指定的注解类型if(clazz.isAnnotationPresent(MyComponent.class)){//获得注解对象MyComponent annotation = clazz.getAnnotation(MyComponent.class);//获得属value属性值String beanName = annotation.value();//判断是否为""if(beanName!=null&&!beanName.equals("")){//存储到Map中去annotationClassMap.put(beanName,clazz);continue;}//如果没有为"",那就把当前类的类名作为beanNameannotationClassMap.put(clazz.getSimpleName(),clazz);}}} catch (Exception exception) {}return annotationClassMap;}public static void main(String[] args) {Map<String, Class> stringClassMap = scanMyComponentAnnotation("com.huanglei");System.out.println(stringClassMap);}
}
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
public @interface MyComponent {String value();
}
@MyComponent("One")
public class OneBean {
}
四、Spring的Bean后处理器
4.1 概念和入门
Bean被实例化过后,在最后缓存到singletonObjects单例池之前,中间会进行Bean的初始化操作,例如:属性的赋值,初始化操作(init-method),其中包含着一个点BeanPostProcessor,这里被称为Bean后处理器。如果实现了这个接口,那么就会被Spring管理,然后Spring会自动调用
public class MyBeanPostProcesser implements BeanPostProcessor {@Overridepublic Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {System.out.println(beanName+"postProcessBeforeInitialization");return null;}@Overridepublic Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {System.out.println(beanName+"postProcessAfterInitialization");return null;}
}
postProcessBeforeInitialization方法和postProcessAfterInitialization方法需要进行手动创建,接口中实现的是null返回值的方法- 两者方法在bena创建之后执行,加入到singletonObjects之前执行
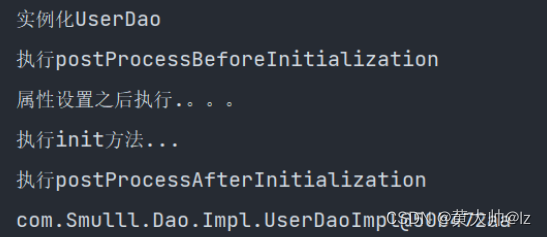
4.2 当中的一些调用方法的顺序
- 先执行bean的构造方法
- 执行before方法
- 执行InitializingBean接口中的afterPropertiesSet()方法
- 执行在xml文件中设置的Bean的init-method方法
- 执行after方法
执行操作如下
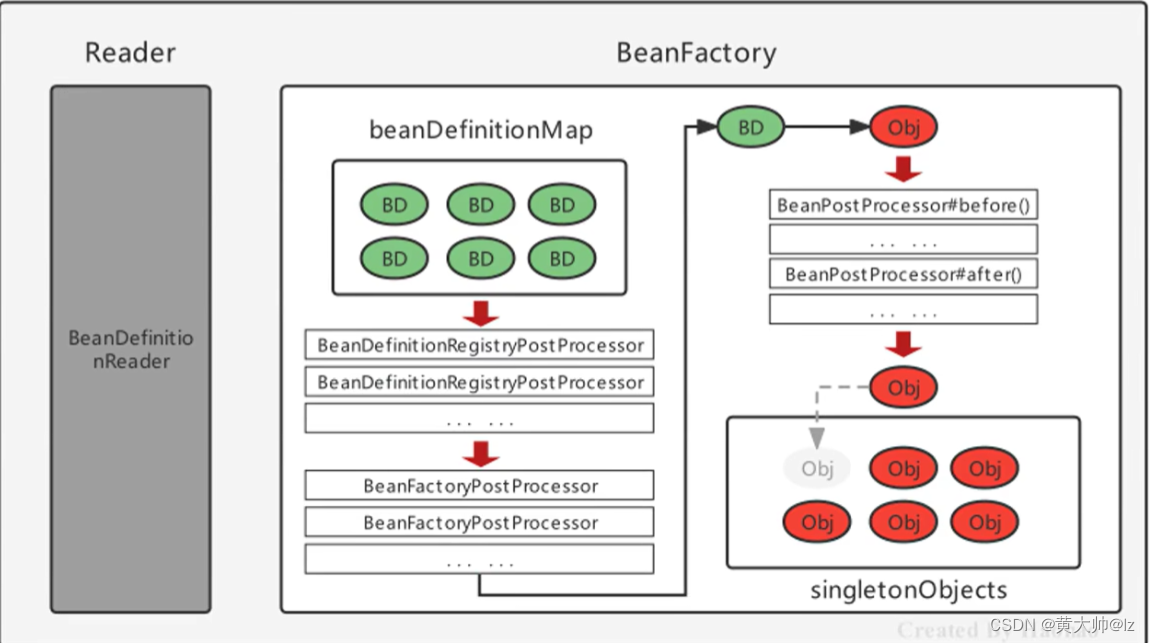
4.3 更加详细的实例化基本操作
BeanPostProcessor在 SpringBean的实例化过程中的体现
五、Spring的生命周期
5.1 概述
Spring Bean的生命周期是从Bean 实例化之后,即通过反射创建出对象之后,导Bean成为一个完整对象,最终储存到单例池中,这个过程被称为SpringBean的生命周期。
- Spring Bean的生命周期大体上分为三个阶段:
- Bean的实例化阶段: Spring框架会取出
BeanDefinition的信息进行判断当前Bean的范围是否是singleton的,是否不是延迟加载的,是否不是FactoryBean等,最终将一个普通的singleton的Bean通过反射进行实例化 - Bean的初始化阶段∶Beane创建之后还仅仅是个”半成品“,还需要对Bean实例的属性进行填充、执行一些Aware接口方法、执行
BeanPostProcessor方法、执行InitializingBean接口的初始化方法、执行自定义初始化init方法等。该阶段是Spring最具技术含量和复杂度的阶段,Aop增强功能,后面要学习的Spring的注解功能等、spring高频面试题Bean的循环引用问题都是在这个阶段体现的 - Bean的完成阶段:经过初始化阶段,Bean就成为了一个完整的Spring Bean,被存储到单例池
singletonObjects中去了,即完成了Spring Bean的整个生命周期。
- Bean的实例化阶段: Spring框架会取出
5.2 初始化阶段执行的步骤
由于Bean的初始化阶段的步骤比较复杂,所以着重研究Bean的初始化阶段
Spring Bean的初始化过程涉及如下几个过程:
Bean实例的属性填充Aware接口属性注入BeanPostProcessor的before()方法回调lnitializingBean接口的初始化方法回调- 自定义初始化方法
init回调 BeanPostProcessor的after()方法回调
5.3 初始化阶段注入属性信息封装
BeanDefinition 中有对当前Bean实体的注入信息通过属性propertyValues进行了存储
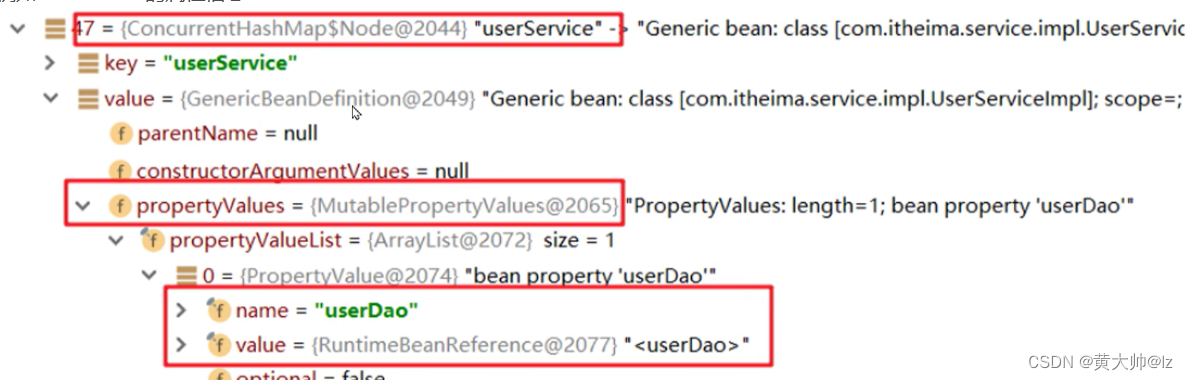
<bean id="userDao" class="com.huanglei.Dao.Impl.UserDaoImpl"></bean><bean id="userService" class="com.huanglei.service.Impl.UserServiceImpl"><property name="dao" ref="userDao"></property><property name="username" value="AAA"></property>
</bean>
5.4、属性注入的三种情况
Spring在进行属性注入时,会分为如下几种情况:
- 注入
普通属性,String、int或存储基本类型的集合时,直接通过set方法的反射设置进去; - 注入
单向对象引用属性时,从容器中getBean获取后通过set方法反射设置进去,如果容器中没有,则先创建被注入对象Bean实例(完成整个生命周期)后,在进行注入操作 - 注入
双向对象引用属性时,就比较复杂了,涉及了循环引用(循环依赖)问题,下面会详细阐述解决方案。
5.4.1 单项注入的代码验证
public class UserServiceImpl implements UserService{private UserDao dao;private String username;public UserServiceImpl() {System.out.println("实例化UserService");}public UserServiceImpl(UserDao dao, String username) {this.dao = dao;this.username = username;}public void setDao(UserDao dao) {System.out.println("执行setDao方法");this.dao = dao;}public void setUsername(String username) {this.username = username;}
}
public class UserDaoImpl implements UserDao{public UserDaoImpl() {System.out.println("实例化UserDao");}
}
userDao在userService前面
<bean id="userDao" class="com.huanglei.Dao.Impl.UserDaoImpl"></bean><bean id="userService" class="com.huanglei.service.Impl.UserServiceImpl"><property name="dao" ref="userDao"></property><property name="username" value="AAA"></property>
</bean>
执行顺序:
- 实例化UserDao
- 实例化UserService
- 执行setDao方法
userDao在userService后面
<bean id="userService" class="com.huanglei.service.Impl.UserServiceImpl"><property name="dao" ref="userDao"></property><property name="username" value="AAA"></property>
</bean><bean id="userDao" class="com.huanglei.Dao.Impl.UserDaoImpl"></bean>总结:
就是说明如果包含了我要调用的Bean对象,有就调用,若无就先创建Bean对象
5.4.2 循环依赖概念及解决方案
多个实体之间相互依赖并形成闭环的情况就叫做 “循环依赖”,也叫做 “循环引用”
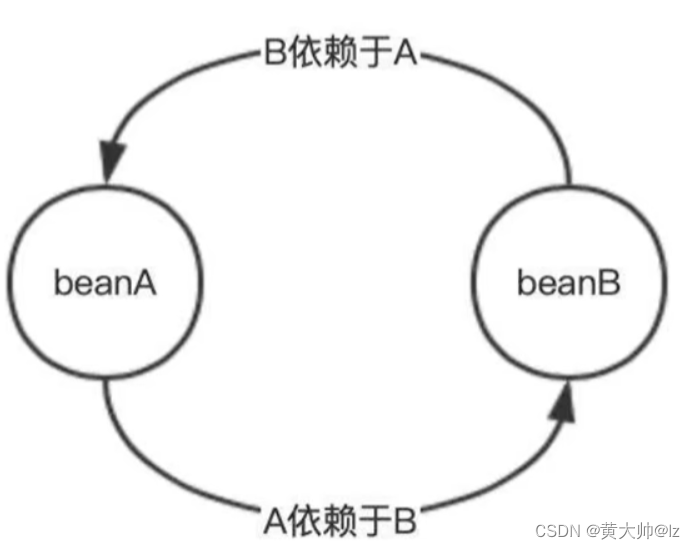
<bean id="userService" class="com.huanglei.service.Impl.UserServiceImpl"><property name="dao" ref="userDao"></property>
</bean><bean id="userDao" class="com.huanglei.Dao.Impl.UserDaoImpl"><property name="service" ref="userService"></property>
</bean>
public class UserDaoImpl implements UserDao{private UserService service; public void setService(UserService service){this.service = service;}
}
public class UserServiceImpl implements UserService{private UserDao dao;public void setDao(UserDao dao) {this.dao = dao;}
}
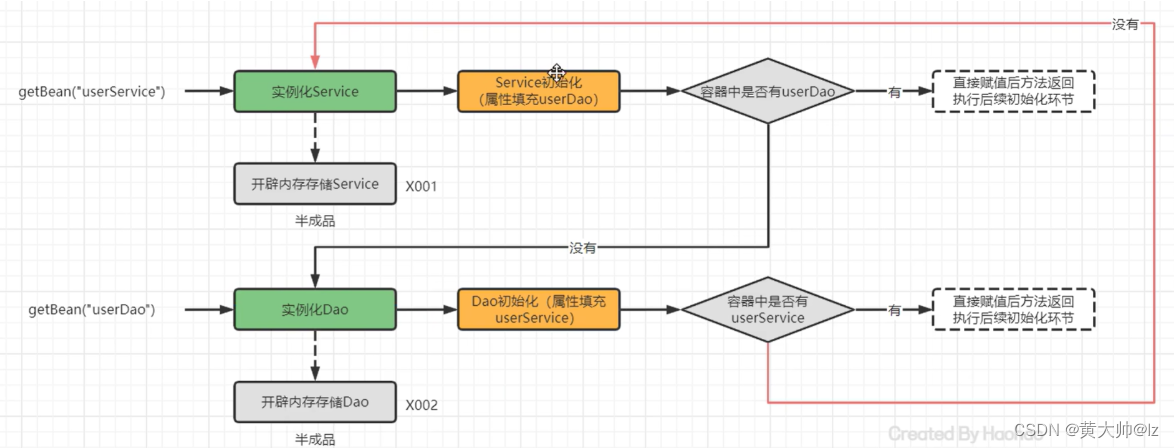
可以利用三级缓存来
5.4.3 三级缓存的设计原理
Spring提供了三级缓存存储完整Bean实例和半成品Bean实例,用于解决循环引用问题
在DefaultListableBeanFactory的上四级父类DefaultSingletonBeanRegistry中提供如下三个Map:
public class DefaultsingletonBeanRegistry ... {//1、最终存储单例Bean成品的容器,即实例化和初始化都完成的Bean,称之为"一级缓存"Map<String,Object> singletonObjects = new ConcurrentHashMap(256);//2、早期Bean单例池,缓存半成品对象,且当前对象已经被其他对象引用了,称之为"二级缓存"Map<String,Object> earlySingletonObjects = new ConcurrentHashMap(16);//3、单例Bean的工厂池,缓存半成品对象,对象未被引用,使用时在通过工厂创建Bean,称之为"三级缓存"Map<String,ObjectFactory<?>> singletonFactories = new HashMap(16);
}
5.5 循环依赖源码流程剖析
UserService和UserDao循环依赖的过程结合上述三级缓存描述一下
- UserService 实例化对象,但尚未初始化,将UserService存储到三级缓存;
- UserService 属性注入,需要UserDao,从缓存中获取,没有UserDao;
- UserDao 实例化对象,但尚未初始化,将UserDao存储到到三级缓存;
- UserDao 属性注入,需要UserService,从三级缓存获取UserService,UserService从三级缓存移入二级缓存;
- UserDao执行其他生命周期过程,最终成为一个完成Bean,存储到一级缓存,删除二三级缓存;
- UserService注入UserDao;
- UserService执行其他生命周期过程,最终成为一个完成Bean,存储到一级缓存,删除二三级缓存。
5.6 Aware接口
Aware接口是一种框架辅助属性注入的一种思想,其他框架中也可以看到类似的接口。框架具备高度封装性,我们接触到的一般都是业务代码,一个底层功能API不能轻易的获取到,但是这不意味着永远用不到这些对象,如果用到了,就可以使用框架提供的类似Aware的接口,让框架给我们注入该对象。
| Aware接口 | 回调方法 | 作用 |
|---|---|---|
| ServletContextAware | setServletContext(ServletContext context) | Spring框架回调方法注入ServletContext对象,web环境下才生效 |
| BeanFactoryAware | setBeanFactory(BeanFactory factory) | Spring框架回调方法注入beanFactory对象 |
| BeanNameAware | setBeanName(String beanName) | Spring框架回调方法注入当前Bean在容器中的beanName |
| ApplicationContextAware | setApplicationContext(ApplicationContext applicationContext) | Spring框架回调方法注入applicationContext对象 |
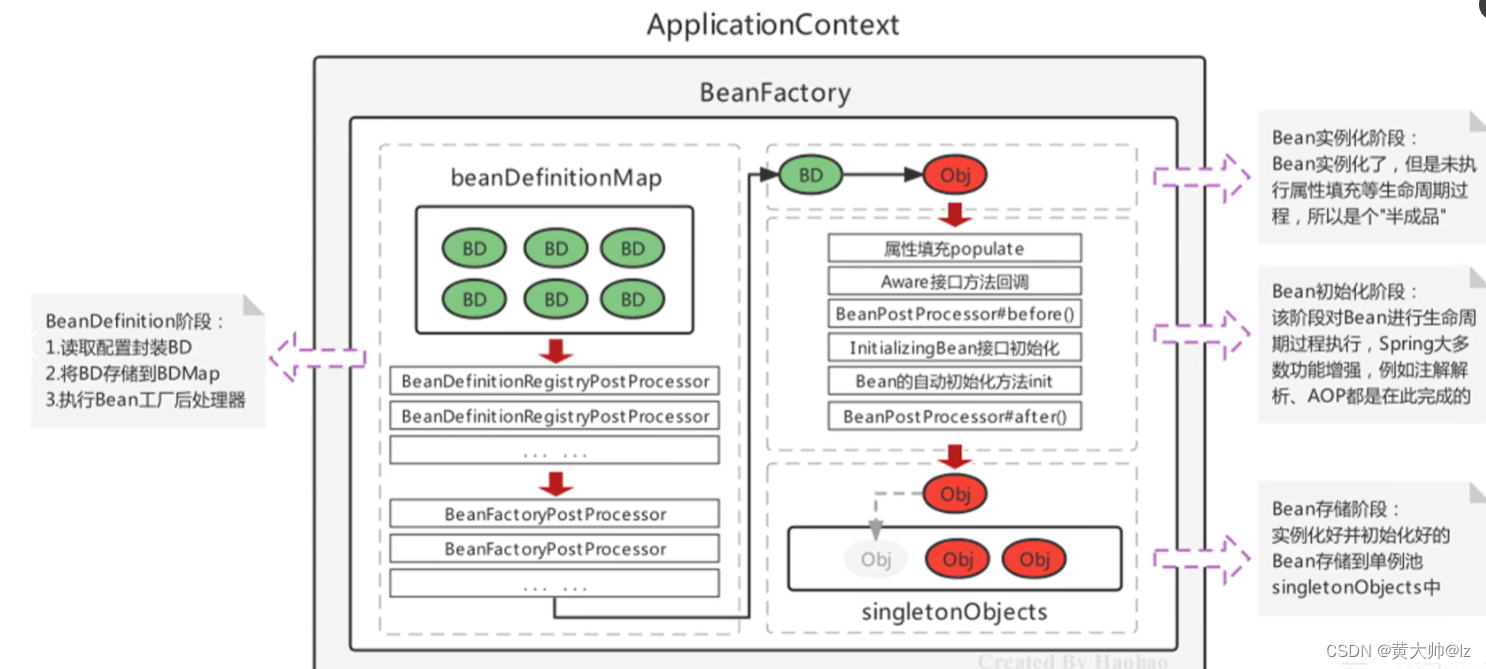
六、IoC容器实例化Bean完整流程图展示
七、Spring xml方式整和第三方框架
- xml整合第三方框架有两种整合方案:
- 不需要自定义名空间,不需要使用Spring的配置文件配置第三方框架本身内容,例如: MyBatis;
- 需要引入第三方框架命名空间,需要使用Spring的配置文件配置第三方框架本身内容,例如:Dubbo。
7.1 Mybatis整合Spring实现
Spring整合MyBatis,之前已经在Spring中简单的配置了SqlSessionFactory,但是这不是正规的整合方式,MyBatis提供了mybatis-spring.jar专门用于两大框架的整合。
Spring整合MyBatis的步骤如下:
- ==导入MyBatis整合Spring的相关坐标; ==
<dependency><groupId>org.mybatis</groupId><artifactId>mybatis-spring</artifactId><!--注意版本,因为版本过低的原因在这里卡了很久!!!--><version>3.0.1</version>
</dependency>
<dependency><groupId>org.springframework</groupId><artifactId>spring-jdbc</artifactId><version>5.2.25.RELEASE</version>
</dependency>
- 编写Mapper和Mapper.xml;
- 配置SqlSessionFactoryBean和MapperScannerConfigurer;
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource"><property name="driverClassName" value="com.mysql.cj.jdbc.Driver"></property><property name="url" value="jdbc:mysql://localhost:3306/itheima"></property><property name="username" value="root"></property><property name="password" value="123456"></property>
</bean>
<!--配置SqlSessionFactoryBean,作用将SqlSessionFactory存储到spring容器-->
<bean class="org.mybatis.spring.SqlSessionFactoryBean"><property name="dataSource" ref="dataSource"></property>
</bean>
<!--MapperScannerConfigurer,作用扫描指定的包,产生Mapper对象存储到Spring容器-->
<bean class="org.mybatis.spring.mapper.MapperScannerConfigurer"><property name="basePackage" value="com.huanglei.mapper"></property>
</bean><bean id="userService" class="com.huanglei.service.Impl.UserServiceImpl"><property name="carMapper" ref="carMapper"></property>
</bean>
- 编写测试代码
7.2、MyBatis整合Spring源码解析
整合包里提供了一个SqlSessionFactoryBean和一个扫描Mapper的配置对象,SqlSessionFactoryBean一旦被实例化,就开始扫描Mapper并通过动态代理产生Mapper的实现类存储到Spring容器中。相关的有如下四个类:
sqlSessionFactoryBean:需要进行配置,用于提供SqlSessionFactory;MapperScannerConfigurer:"需要进行配置,用于扫描指定mapper注册BeanDefinition;MapperFactoryBean: Mapper的FactoryBean,获得指定Mapper时调用getObject方法;ClassPathMapperScanner: definition.setAutowireMode(2)修改了自动注入状态,所以MapperFactoryBean中的setSqlSessionFactory会自动注入进去。
7.3 加载外部properties文件
Spring整合其他组件时就不像MyBatis这么简单了,例如Dubbo框架在于Spring进行整合时,要使用Dubbo提供的命名空间的扩展方式,自定义了一些Dubbo的标签
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xmlns:dubbo="http://dubbo.apache.org/schema/dubbo"xsi:schemaLocation="http://www.springframework.org/schema/beanshttp://www.springframework.org/schema/beans/spring-beans.xsdhttp://dubbo.apache.org/schema/dubbohttp://dubbo.apache.org/schema/dubbo/dubbo.xsd"><!-- 配置Dubbo应用信息 --><dubbo:application name="your-application-name" /><!-- 配置注册中心 --><dubbo:registry address="zookeeper://127.0.0.1:2181" /><!-- 配置服务提供者 --><dubbo:protocol name="dubbo" port="20880" /><dubbo:service interface="com.example.YourServiceInterface" ref="yourServiceBean" /><!-- 配置其他Bean --><!-- 消费者配置 --><dubbo:consumer check="false" timeout="1000" retries="0"/>
</beans>
通过配置context文件来加载外部properties文件
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xmlns:context="http://www.springframework.org/schema/context"xsi:schemaLocation="http://www.springframework.org/schema/beanshttp://www.springframework.org/schema/beans/spring-beans.xsdhttp://www.springframework.org/schema/contexthttp://www.springframework.org/schema/context/spring-context.xsd"><!--通过context加载properties文件--><context:property-placeholder location="classpath:jdbc.properties"/><bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource"><property name="driverClassName" value="${jdbc.driver}"></property><property name="url" value="${jdbc.url}"></property><property name="username" value="${jdbc.username}"></property><property name="password" value="${jdbc.password}"></property></bean><!--配置SqlSessionFactoryBean,作用将SqlSessionFactory存储到spring容器--><bean class="org.mybatis.spring.SqlSessionFactoryBean"><property name="dataSource" ref="dataSource"></property></bean><!--MapperScannerConfigurer,作用扫描指定的包,产生Mapper对象存储到Spring容器--><bean class="org.mybatis.spring.mapper.MapperScannerConfigurer"><property name="basePackage" value="com.huanglei.mapper"></property></bean><bean id="userService" class="com.huamglei.service.Impl.UserServiceImpl"><property name="carMapper" ref="carMapper"></property></bean>
</beans>
7.4、自定义空间步骤
- 将自定义标签的约束与物理约束文件与网络约束名称的约束以键值对形式存储到一个
spring.schemas文件里,该文件存储在类加载路径的META-INF里,Spring会自动加载到; - 将自定义命名空间的名称与自定义命名空间的处理器映射关系以键值对形式存在到一个叫
spring.handlers文件里,该文件存储在类加载路径的 META-INF里,Spring会自动加载到; - 准备好NamespaceHandler,如果命名空间只有一个标签,那么直接在
parse方法中进行解析即可,一般解析结果就是注册该标签对应的BeanDefinition。如果命名空间里有多个标签,那么可以在init方法中为每个标签都注册一个BeanDefinitionParser,在执行NamespaceHandler的parse方法时在分流给不同的
BeanDefinitionParser进行解析(重写doParse方法即可)。