国内重大新闻2023什么是搜索引擎优化的核心
Java也可用于开发一些动画。所谓动画,就是间隔一定的时间(通常小于0 . 1秒 )重新绘制新的图像,两次绘制的图像之间差异较小,肉眼看起来就成了所谓的动画 。
为了实现间隔一定的时间就重新调用组件的 repaint()方法,可以借助于 Swing 提供的Timer类,Timer类是一个定时器, 它有如下一个构造器 :
Timer(int delay, ActionListener listener): 每间隔 delay 毫秒,系统自动触发 ActionListener 监听器里的事件处理器方法,在方法内部我们就可以调用组件的repaint方法,完成组件重绘。
案例2:
使用AWT画图技术及Timer定时器,完成下图中弹球小游戏。
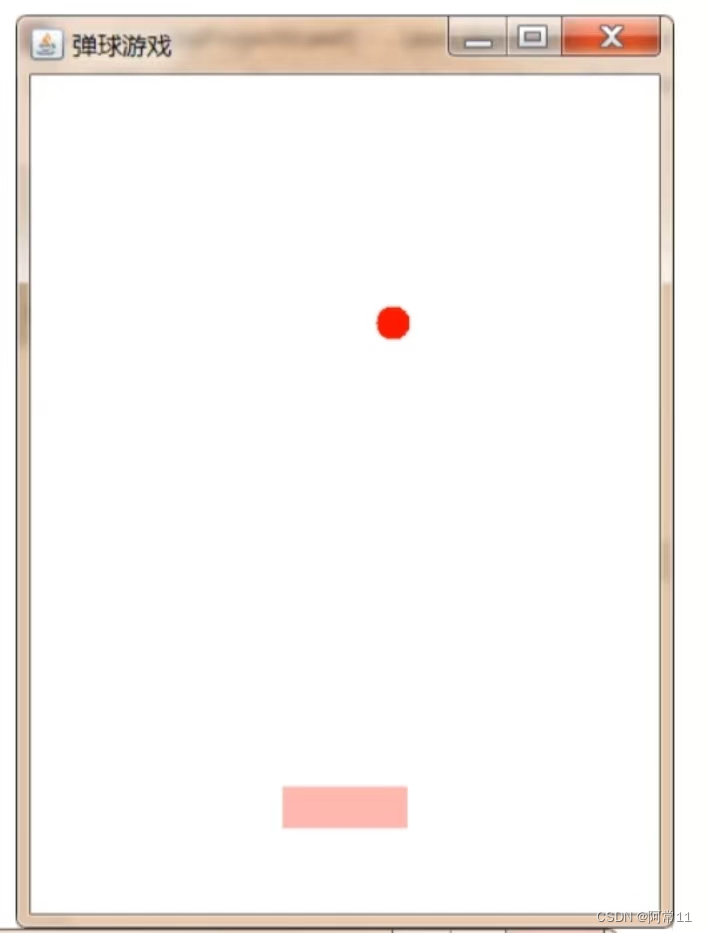

使用键盘左右键来控制粉色球拍的水平移动,小球碰到窗口边界和球拍会反弹,并且落到球拍下方就会游戏结束并出现结束界面。
package Draw;import java.awt.*;
import java.awt.event.*;
import javax.swing.*;public class PinBall {//创建窗口对象private Frame frame = new Frame("弹球游戏");//1.设置桌面和球拍各自的宽度和高度private final int TABLE_WIDTH = 300;private final int TABLE_HEIGHT = 400;private final int RACKET_WIDTH = 60;private final int RACKET_HEIGHT = 20;//2.设置小球的大小,即小球的直径private final int BALL_SIZE = 16;//3.记录小球的坐标//注意坐标原点是窗口左上角private int ballX = 120; //并且初始化小球的坐标private int ballY = 20;//4.设置小球在X和Y方向上分别移动的速度private int speedY = 10;private int speedX = 5;//5.记录球拍的坐标private int racketX = 120;private final int racketY = 340; //球拍的Y坐标一直不变,即球拍一直在水平移动//6.游戏是否结束的标识private boolean isOver = false;//7.定时器:声明一个定时器private Timer timer;//8.画布:自定义一个类,继承Canvas,充当画布//只实现画面的绘制,不管游戏逻辑的变换private class MyCanvas extends Canvas {@Overridepublic void paint(Graphics g) {//TODO 在这里绘制内容if(isOver){//游戏结束g.setColor(Color.BLUE); //设置字体颜色g.setFont(new Font("Times", Font.BOLD,30)); //设置字体样式g.drawString("游戏结束!",50,200); //设置内容和位置(位置大概居中)}else {//游戏中//绘制小球g.setColor(Color.RED); //设置小球的颜色g.fillOval(ballX,ballY,BALL_SIZE,BALL_SIZE); //设置小球的坐标和大小//绘制球拍g.setColor(Color.pink); //设置球拍的颜色g.fillRect(racketX,racketY,RACKET_WIDTH,RACKET_HEIGHT); //设置球拍的坐标和大小}}}//9.画笔:创建绘画区域MyCanvas drawArea = new MyCanvas();public void init() {//组装视图,游戏逻辑的控制//如何控制小球和球拍的变换//10.完成球拍坐标的变化,通过键盘左右键来实现KeyListener listener = new KeyAdapter() {@Overridepublic void keyPressed(KeyEvent e) {//获取当前按下的键int keyCode = e.getKeyCode();if(keyCode == KeyEvent.VK_LEFT) { //这个KeyEvent.VK_LEFT意味这是键盘的左箭头//向左移动//TODOif(racketX <= 10) racketX = 0;else racketX -= 10;}if(keyCode == KeyEvent.VK_RIGHT) {//向右移动if(racketX > (TABLE_WIDTH - RACKET_WIDTH - 10)) racketX = TABLE_WIDTH - RACKET_WIDTH;else racketX += 10;}}};//给Frame和drawArea注册监听器frame.addKeyListener(listener);drawArea.addKeyListener(listener);//11.小球坐标的控制ActionListener task = new ActionListener() {@Overridepublic void actionPerformed(ActionEvent e) {//更新小球的坐标,重绘界面//根据边界范围,修正小球的速度 ,即碰到边界会反弹if(ballX <= 0 || ballX >= (TABLE_WIDTH-BALL_SIZE)) {//碰到左边界和右边界speedX = -speedX;}if(ballY <= 0 || (ballY>racketY-BALL_SIZE && ballX>=racketX && ballX <racketX+RACKET_WIDTH)) {//碰到上边界,以及碰到球拍,判定条件是小球y>球拍y,并且小球在球拍宽度的范围内speedY = -speedY;}if(ballY>racketY-BALL_SIZE && (ballX < racketX || ballX >racketX+RACKET_WIDTH)){//当前小球超出了球拍能接到的范围,游戏结束//停止定时器timer.stop();//修改游戏结束的标记isOver = true;//重绘界面drawArea.repaint();}ballX += speedX;ballY += speedY;//重绘界面drawArea.repaint();}};timer = new Timer(100,task); //一百毫秒执行一次timer.start();//组装界面drawArea.setPreferredSize(new Dimension(TABLE_WIDTH,TABLE_HEIGHT));frame.add(drawArea);//设置frame最佳大小和可见性frame.pack();frame.setVisible(true);}public static void main(String[] args) {new PinBall().init();}
}