三门峡市住房和城乡建设局网站河南seo外包
目录
开发环境
数据描述
功能需求
数据准备
数据分析
RDD操作
Spark SQL操作
创建Hbase数据表
创建外部表
统计查询
开发环境
Hadoop+Hive+Spark+HBase
启动Hadoop:start-all.sh
启动zookeeper:zkServer.sh start
启动Hive:
nohup hiveserver2 1>/dev/null 2>&1 &
beeline -u jdbc:hive2://192.168.152.192:10000
启动Hbase:
start-hbase.sh
hbase shell
启动Spark:
spark-shell
数据描述
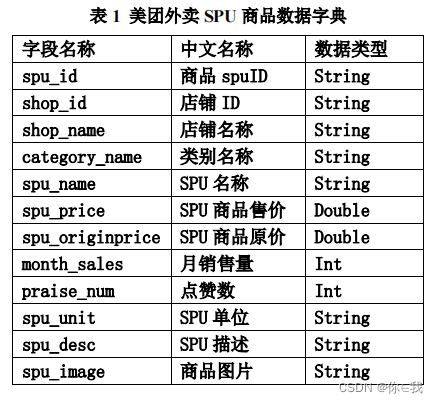
meituan_waimai_meishi.csv 是美团外卖平台的部分外卖 SPU(Standard Product Unit , 标准产品单元)数据,包含了外卖平台某地区一时间的外卖信息。具体字段说明如下:
功能需求
数据准备
创建文件
hdfs dfs -mkdir -p /app/data/exam上传目录
hdfs dfs -put ./meituan_waimai_meishi.csv /app/data/exam查看文件行数
hdfs dfs -cat /app/data/exam/meituan_waimai_meishi.csv | wc -l
数据分析
RDD操作
val spark: SparkSession = SparkSession.builder().master("local[*]").appName("exam").getOrCreate()val sc: SparkContext = spark.sparkContextval lines: RDD[String] = sc.textFile("hdfs://192.168.152.192:9000/app/data/exam/meituan_waimai_meishi.csv")val lines1: RDD[Array[String]] = lines.filter(x => x.startsWith("spu_id") == false).map(x => x.split(","))lines1.map(x => (x(2), 1)).reduceByKey(_ + _).collect().foreach(println)②统计每个店铺的总销售额。
lines1.map(x => (x(2), Try(x(5).toDouble).toOption.getOrElse(0.0) *Try(x(7).toInt).toOption.getOrElse(0))).reduceByKey(_ + _).collect().foreach(println)③统计每个店铺销售额最高的前三个商品,输出内容包括店铺名,商品名和销售额,其
//方法一lines1.map(x => (x(2), x(4), Try(x(5).toDouble).toOption.getOrElse(0.0) *Try(x(7).toInt).toOption.getOrElse(0))).filter(x => x._3 > 0).groupBy(x => x._1).mapValues(value => value.toList.sortBy(x => -x._3).take(3)) //负号(-)降序.flatMapValues(x => x).collect().foreach(println)//方法二lines1.map(x => (x(2), x(4), Try(x(5).toDouble).toOption.getOrElse(0.0) *Try(x(7).toInt).toOption.getOrElse(0))).filter(x => x._3 > 0).groupBy(x => x._1).flatMap(x => x._2.toList.sortBy(y => 0 - y._3).take(3)).foreach(println)//方法三lines1.map(x => (x(2), x(4), Try(x(5).toDouble).toOption.getOrElse(0.0) *Try(x(7).toInt).toOption.getOrElse(0))).filter(x => x._3 > 0).groupBy(x => x._1).map(x => {var shop_name: String = x._1;var topThree: List[(String, String, Double)] = x._2.toList.sortBy(item => 0 - item._3).take(3);var shopNameAndSumMoney: List[String] = topThree.map(it => it._2 + " " + it._3);(shop_name, shopNameAndSumMoney)}).foreach(println)Spark SQL操作
val spark: SparkSession = SparkSession.builder().master("local[*]").appName("exam").getOrCreate()val sc: SparkContext = spark.sparkContextval spuDF: DataFrame = spark.read.format("csv").option("header", true).load("hdfs://192.168.152.192:9000/app/data/exam/meituan_waimai_meishi.csv")spuDF.createOrReplaceTempView("sputb")①统计每个店铺分别有多少商品(SPU)。
spark.sql("select * from sputb").show()spark.sql("select shop_name,count(shop_name) as num from sputb group by shop_name").show()③统计每个店铺销售额最高的前三个商品,输出内容包括店铺名,商品名和销售额,其 中销售额为 0 的商品不进行统计计算,例如:如果某个店铺销售为 0,则不进行统计。
spark.sql("select shop_name, sum(spu_price * month_sales) as sumMoney from sputb group by shop_name").show()
创建Hbase数据表
在 HBase 中创建命名空间(namespace)exam,在该命名空间下创建 spu 表,该表下有
create 'exam:spu','result'创建外部表
请 在 Hive 中 创 建 数 据 库 spu_db
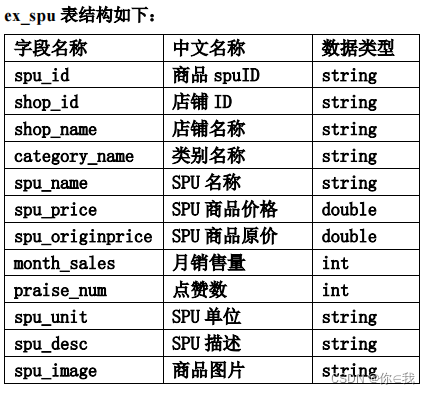
create database spu_db;在 该 数 据 库 中 创 建 外 部 表 ex_spu 指 向 /app/data/exam 下的测试数据 ;
create external table if not exists ex_spu (spu_id string,shop_id string,shop_name string,category_name string,spu_name string,spu_price double,spu_originprice double,month_sales int,praise_num int,spu_unit string,spu_desc string,spu_image string
)
row format delimited fields terminated by ","
stored as textfile location "/app/data/exam"
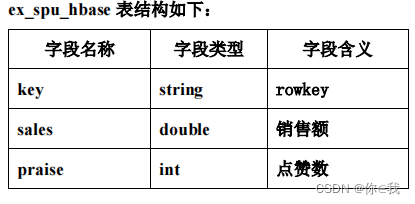
tblproperties ("skip.header.line.count"="1");创建外部表 ex_spu_hbase 映射至 HBase 中的 exam:spu 表的 result 列族
create external table if not exists ex_spu_hbase
(key string,sales double,praise int
)
stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' with
serdeproperties ("hbase.columns.mapping"=":key,result:sales,result:praise")
tblproperties ("hbase.table.name"="exam:spu");统计查询
insert into ex_spu_hbase
select concat(tb.shop_id,tb.shop_name) as key, tb.sales,tb.praise from
(select shop_id,shop_name,sum(spu_price*month_sales) as sales, sum(praise_num) as praise
from ex_spu group by shop_id,shop_name) tb;hive > select * from ex_spu_hbase;hbase(main):007:0> scan 'exam:spu'