建立网站的公司有哪些国外seo
关注微信公众号 “程序员小胖” 每日技术干货,第一时间送达!
引言
分布式事务模型是分布式系统设计的核心,关键在于保证数据一致性和事务完整性,尤其强调强一致性。诸如2PC、3PC、Saga、TCC等模型与协议,应运而生以解决分布式ACID实现难题,包括处理网络延迟、节点故障及并发控制等。它们追求在一致性和系统性能、可用性上的平衡。在微服务和云计算时代,高效灵活的分布式事务管理对于构建可靠、高性能系统尤为关键,对技术人员来说,精通这些模型及其应用场景,对提升系统质量和用户体验至关重要。
2PC
两阶段提交(2PC)故名思义,是有两个步骤组成的.其中涉及到两个角色 TM(事务管理器)和 RM(资源管理器)
准备阶段(Phase 1)
事务协调者向所有参与者发送事务预提交请求,询问是否准备好提交事务。
TM(事务管理器)通知各个RM(资源管理器)准备提交它们的事务分支。如果RM判断自己进行的工作可以被提交,那就对工作内容进行持久化,再给TM肯定答复;要是发生了其他情况,那给TM的都是否定答复。
提交阶段(Phase 2)
如果协调者收到所有参与者的“准备成功”响应,它会向所有参与者发送“提交事务”命令;
TM根据阶段1各个RM prepare的结果,决定是提交还是回滚事务。如果所有的RM都prepare成功,那么TM通知所有的RM进行提交;如果有RM prepare失败的话,则TM通知所有RM回滚自己的事务分支。

以mysql数据库为例,在第一阶段,事务管理器向所有涉及到的数据库服务器发出prepare"准备提交"请求,数据库收到请求后执行数据修改和日志记录等处理,处理完成后只是把事务的状态改成"可以提交",然后把结果返回给事务管理器。
如果第一阶段中所有数据库都prepare成功,那么事务管理器向数据库服务器
发出"确认提交"请求,数据库服务器把事务的"可以提交"状态改为"提交完成"状态,然后返回应答。如果在第一阶段内有任何一个数据库的操作发生了错误,或者事务管理器收不到某个数据库的回应,则认为事务失败,回撤所有数据库的事务。数据库服务器收不到第二阶段的确认提交请求,也会把"可以提交"的事务回撤。
使用场景
金融交易:如银行间的资金转账,确保资金不会凭空产生或消失。
库存管理系统:在电子商务中,确保商品的库存数量准确无误。
import java.util.List;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;// 简化版的参与者
interface Participant {boolean prepare();void commit();void rollback();
}// 简化的协调者
class Coordinator {private List<Participant> participants;private ExecutorService executor;public Coordinator(List<Participant> participants) {this.participants = participants;this.executor = Executors.newFixedThreadPool(participants.size());}public void startTransaction() {try {List<Future<Boolean>> prepareResults = preparePhase();if (allTrue(prepareResults)) {commitPhase();} else {rollbackPhase();}} finally {executor.shutdown();}}private List<Future<Boolean>> preparePhase() {return executor.invokeAll(participants, preparingTask());}private void commitPhase() {participants.forEach(Participant::commit);}private void rollbackPhase() {participants.forEach(Participant::rollback);}private boolean allTrue(List<Future<Boolean>> results) throws InterruptedException {for (Future<Boolean> result : results) {if (!result.get()) return false;}return true;}private Runnable preparingTask() {return () -> {// 模拟参与者的行为,实际中参与者会在此执行本地事务并返回结果return true; // 返回true表示准备成功,false表示失败};}
}// 示例参与者
class MockParticipant implements Participant {@Overridepublic boolean prepare() {// 实现本地事务的预提交检查逻辑return true; // 假设总是成功}@Overridepublic void commit() {// 执行事务的提交操作System.out.println("Committing transaction...");}@Overridepublic void rollback() {// 执行事务的回滚操作System.out.println("Rolling back transaction...");}
}public class TwoPhaseCommitDemo {public static void main(String[] args) {List<Participant> participants = List.of(new MockParticipant(), new MockParticipant());Coordinator coordinator = new Coordinator(participants);coordinator.startTransaction();}
}
2PC存在的问题
二阶段提交看起来确实能够提供原子性的操作,但是不幸的是,二阶段提交还是有几个缺点的:
- 同步阻塞问题
2PC 中的参与者是阻塞的。在第一阶段收到请求后就会预先锁定资源,一直到 commit 后才会释放。
- 单点故障
由于协调者的重要性,一旦协调者TM发生故障,参与者RM会一直阻塞下去。尤其在第二阶段,协调者发生故障,那么所有的参与者还都处于锁定事务资源的状态中,而无法继续完成事务操作。
- 数据不一致
若协调者第二阶段发送提交请求时崩溃,可能部分参与者收到commit请求提交了事务,而另一部
分参与者未收到commit请求而放弃事务,从而造成数据不一致的问题。
3PC
三阶段提交(3PC, Three-Phase Commit)模型是对两阶段提交(2PC)的一个改进,旨在减少阻塞范围并提高系统的可用性,同时仍然追求强一致性。3PC通过引入预提交阶段来减少参与者在不确定状态下的时间,从而降低了事务长时间阻塞的风险。
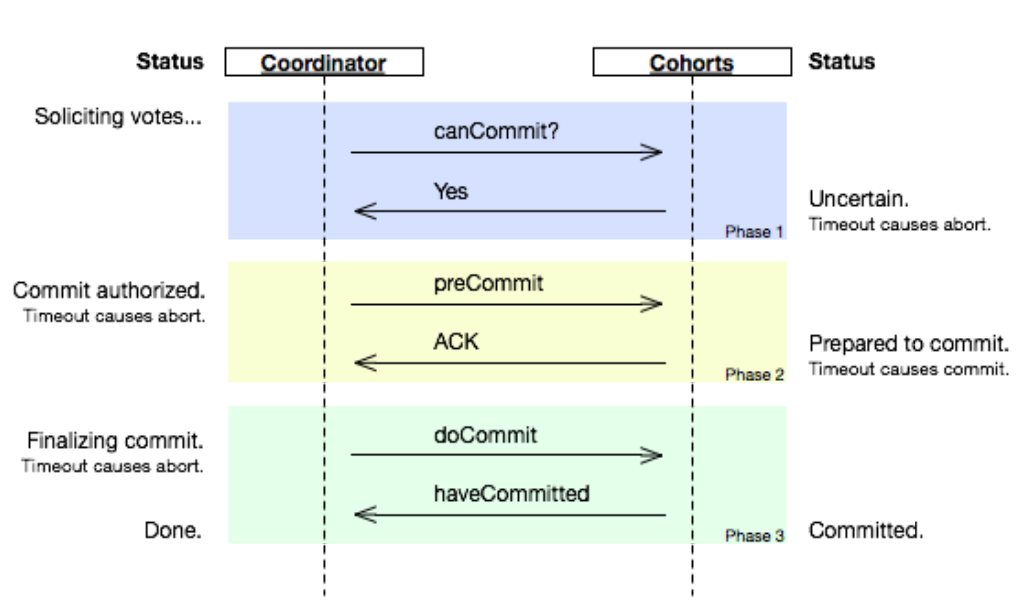
CanCommit阶段
3PC的CanCommit阶段其实和2PC的准备阶段很像。协调者向参与者发送commit请求,参与者如果可以提交就返
回Yes响应,否则返回No响应。
- 事务询问 协调者向参与者发送CanCommit请求。询问是否可以执行事务提交操作。然后开始等待参与者的响
应。 - 响应反馈 参与者接到CanCommit请求之后,正常情况下,如果其自身认为可以顺利执行事务,则返回Yes响应,并进入预备状态。否则反馈No
PreCommit阶段
协调者根据参与者的反应情况来决定是否可以记性事务的PreCommit操作。根据响应情况,有以下两种可能。
假如协调者从所有的参与者获得的反馈都是Yes响应,那么就会执行事务的预执行。
- 发送预提交请求 协调者向参与者发送PreCommit请求,并进入Prepared阶段。
- 事务预提交 参与者接收到PreCommit请求后,会执行事务操作,并将undo和redo信息记录到事务日志中。
- 响应反馈 如果参与者成功的执行了事务操作,则返回ACK响应,同时开始等待最终指令。
假如有任何一个参与者向协调者发送了No响应,或者等待超时之后,协调者都没有接到参与者的响应,那么就执行事务的中断。
- 发送中断请求 协调者向所有参与者发送abort请求。
- 中断事务 参与者收到来自协调者的abort请求之后(或超时之后,仍未收到协调者的请求),执行事务的中断。
doCommit阶段
该阶段进行真正的事务提交,也可以分为以下两种情况
场景1:执行提交
- 发送提交请求 协调接收到参与者发送的ACK响应,那么他将从预提交状态进入到提交状态。并向所有参与者发送doCommit请求。
- 事务提交 参与者接收到doCommit请求之后,执行正式的事务提交。并在完成事务提交之后释放所有事务资源。
- 响应反馈 事务提交完之后,向协调者发送Ack响应。
- 完成事务 协调者接收到所有参与者的ack响应之后,完成事务。
场景 2:中断事务
协调者没有接收到参与者发送的ACK响应(可能是接受者发送的不是ACK响应,也可能响
应超时),那么就会执行中断事务。
- 发送中断请求 协调者向所有参与者发送abort请求
- 事务回滚 参与者接收到abort请求之后,利用其在阶段二记录的undo信息来执行事务的回滚操作,并在完成
回滚之后释放所有的事务资源。 - 反馈结果 参与者完成事务回滚之后,向协调者发送ACK消息
- 中断事务 协调者接收到参与者反馈的ACK消息之后,执行事务的中断。
看到这里其实我们能看出来3PC是2PC的升级版本。三阶段提交相较于两阶段提交主要有两个改动点:
- 引入超时机制。同时在协调者和参与者中都引入超时机制。
2.在第一阶段和第二阶段中插入一个准备阶段。保证了在最后提交阶段之前各参与节点的状态是一致的。也就是说,除了引入超时机制之外,3PC把2PC的准备阶段再次一分为二,这样三阶段提交就有CanCommit、PreCommit、DoCommit三个阶段。
使用场景
- 金融交易:确保资金在多个账户间转移过程中的精确和不可逆。
- 分布式数据库同步:在多副本数据库系统中,确保数据更改在所有节点上一致。
- 关键业务流程:如保险索赔处理,需要高度一致性的步骤执行。
class Coordinator {List<Participant> participants;void start3PCTransaction() {// 第一阶段:Prepareif (allParticipantsReadyToPrepare()) {// 第二阶段:PreCommitif (allParticipantsReadyToPreCommit()) {// 第三阶段:CommitcommitTransaction();} else {abortTransaction();}} else {abortTransaction();}}private boolean allParticipantsReadyToPrepare() {// 实现逻辑:询问所有参与者是否准备好return true; // 简化处理}private boolean allParticipantsReadyToPreCommit() {// 实现逻辑:询问所有参与者是否准备好预提交return true; // 简化处理}private void commitTransaction() {// 实现逻辑:通知所有参与者提交事务}private void abortTransaction() {// 实现逻辑:通知所有参与者事务失败,需要回滚}
}interface Participant {boolean canPrepare();boolean canPreCommit();void commit();void rollback();
}// 示例参与者
class MockParticipant implements Participant {@Overridepublic boolean canPrepare() { return true; }@Overridepublic boolean canPreCommit() { return true; }@Overridepublic void commit() { System.out.println("Committing..."); }@Overridepublic void rollback() { System.out.println("Rolling Back..."); }
}
结语
总结而言,分布式事务模型在构建强一致性分布式系统中扮演着不可或缺的角色,是确保数据一致性和事务完整性的基石。面对分布式环境的固有挑战,诸如两阶段提交(2PC)、三阶段提交(3PC),为开发者提供了实现强一致性的多样化手段。这些模型通过精心设计的协议,在数据一致性、系统可用性与性能之间寻找微妙的平衡点。