做公司网站宣传公司seo日常工作都做什么的
inno
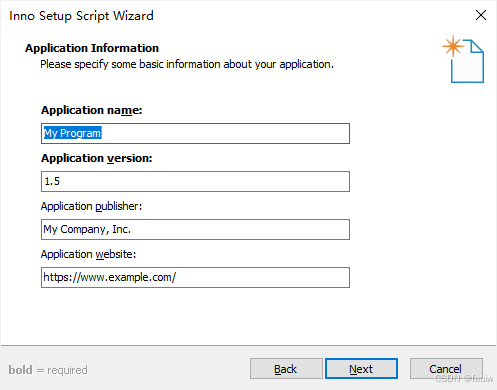
设置应用名称,版本等信息
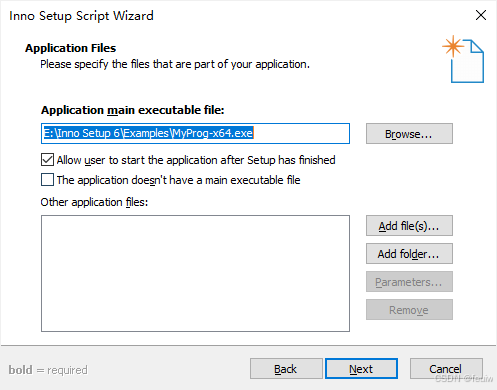
选择exe文件,和添加文件夹,Release文件夹
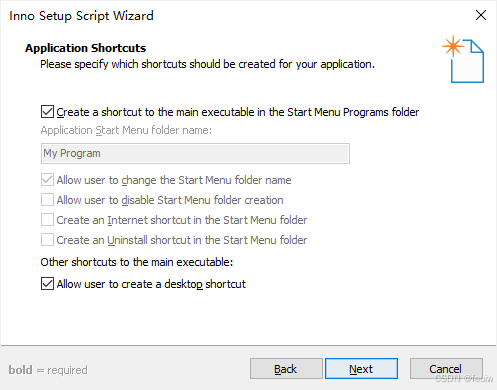
创建图标
设置输出选择
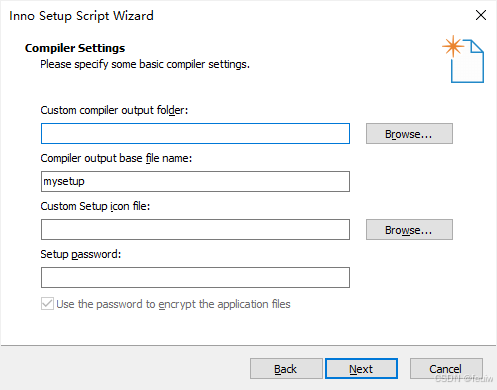
然后保存运行程序。
Microsoft Visual Studio Installer Projects
下载扩展
【扩展】-> 【管理扩展】-> 搜索,安装

打包
创建setup 项目
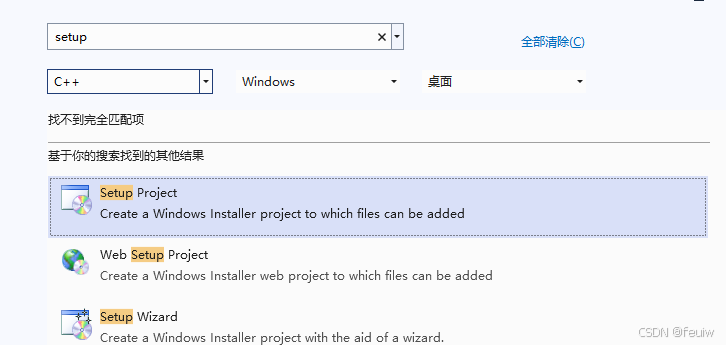

添加文件及文件夹
点击 Application Folder 然后 把 要打包的项目 Release 整个文件夹里文件及文件夹复制到右侧

创建快捷方式及图标
右击.exe 然后选择 Create Short
创建后剪切到 User’Desktop 中,并修改名称

选中 myapp,在属性页面添加图标
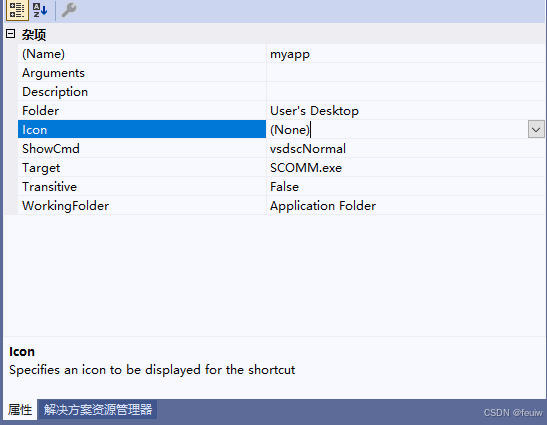
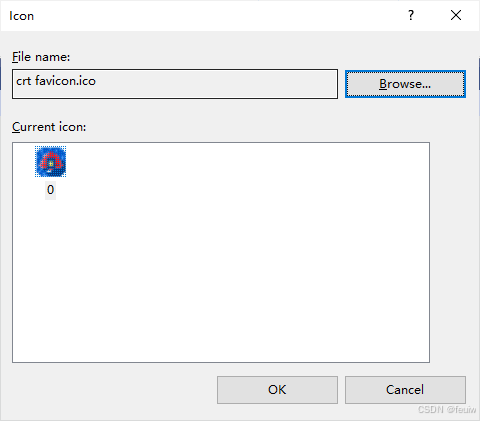
生成msi
选择 Release, 然后点击 生成。
