做网站的空间费用要多少成都网站设计公司
Winform使用Webview2加载本地HTML页面并互相通信
- 往期目录
- 本节目标
- 核心代码
- 实现HTML代码
- 实现的窗体Demo2代码
- 效果图
往期目录
往期相关文章目录
专栏目录
本节目标
- 实现刷新按钮
- 点击
C# winform按钮可以调用C# winform代码显示到html上 - 点击
HTML按钮可以调用C# winform代码更改html按钮字体
核心代码
- C# -> html
this.mainView2.ExecuteScriptAsync("调用方(发送消息..)");
- html->C#
-
- 确保mainView2的CoreWebView2异步初始化完成
this.mainView2.EnsureCoreWebView2Async(null);
-
- 在webview2的CoreWebView初始化之后设置属性
//coreWebview2完成时发生。在完成时进行一系列设置。this.mainView2.CoreWebView2InitializationCompleted += (object sender, CoreWebView2InitializationCompletedEventArgs e)=>{this.mainView2.CoreWebView2.Settings.IsScriptEnabled = true;
}
-
- 在coreWebview2完成时添加
WebMessageReceived监听。如下代码。
- 在coreWebview2完成时添加
this.mainView2.CoreWebView2InitializationCompleted += (object sender, CoreWebView2InitializationCompletedEventArgs e) => {this.mainView2.CoreWebView2.Settings.IsScriptEnabled = true;this.mainView2.CoreWebView2.WebMessageReceived += CoreWebView2_WebMessageReceived;};
-
- 实现接受方法
/// <summary>
/// 页面发送消息时,后台接受信息
/// </summary>private void CoreWebView2_WebMessageReceived(object sender, CoreWebView2WebMessageReceivedEventArgs e)
{// e.WebMessageAsJson.ToString();为获取到的JSON字符串
}
实现HTML代码
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>Demo2TextHTMl</title>
</head><script>// 声明一个函数,在winform端 进行调用,并将调用的数值展示到页面上function winformToHtmlText(text){document.querySelector('.test1').innerHTML=text;}//当前函数通过html处罚更改Winform界面上的按钮字体function htmlToWinformText() {alert("开始发送");try {chrome.webview.postMessage("创建按钮点击更改winform窗体上的按钮字体");chrome.webview.postMessage({ b: "创建按钮点击更改winform窗体上的按钮字体" });} catch (e) {alert(e.message)}}</script>
<body><div class="test1"></div><div><button onclick="htmlToWinformText()">创建按钮点击更改winform窗体上的按钮字体</button></div>
</body>
</html>
实现的窗体Demo2代码
public partial class Demo2 : Form{public Demo2(){InitializeComponent();this.mainView2.EnsureCoreWebView2Async(null);}/// <summary>/// 窗体加载程序/// </summary>/// <param name="sender"></param>/// <param name="e"></param>private async void Demo2_Load(object sender, EventArgs e){//获取可执行目录地址string exePath = Application.StartupPath;//拼接计算html页面路径string relativePath = "../../HTML/Demo2.html";string path = Path.GetFullPath(Path.Combine(exePath, relativePath));this.mainView2.Source = new Uri(@"file:///" + path);//初始化 coreWebview2完成时发生。在完成时进行一系列设置。this.mainView2.CoreWebView2InitializationCompleted += (object sender2, CoreWebView2InitializationCompletedEventArgs e2) => {this.mainView2.CoreWebView2.Settings.IsScriptEnabled = true;//创建页面发送消息时,后台接受信息事件this.mainView2.CoreWebView2.WebMessageReceived += CoreWebView2_WebMessageReceived;};}/// <summary>/// html页面发送消息时,后台接受信息/// </summary>private void CoreWebView2_WebMessageReceived(object sender, CoreWebView2WebMessageReceivedEventArgs e){this.butByHtmlChange.Text = e.WebMessageAsJson.ToString();}/// <summary>/// 调用html函数/// </summary>private void btnSendToHtml_Click(object sender, EventArgs e){string text = "这是一段从窗体发送到HTMl的文字!";this.mainView2.ExecuteScriptAsync($"winformToHtmlText('{text}')");} /// <summary>/// 刷新按钮/// </summary>/// <param name="sender"></param>/// <param name="e"></param>private void btnRefresh_Click(object sender, EventArgs e){this.mainView2.Reload();}}
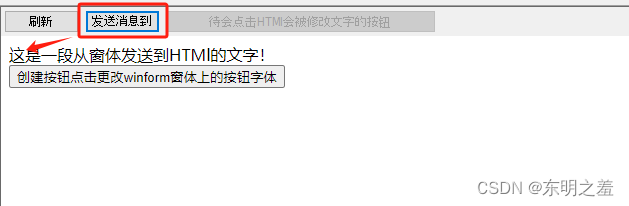
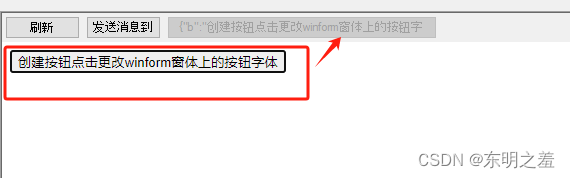
效果图
- 从窗体发送到HTMl的文字
- 从HTML 修改窗体按钮文字
往期相关文章目录
专栏目录