网站备案 不备案网络营销策略存在的问题
在学习完进阶C指针之后,可以来做一些笔试题来进行提升、巩固,小编在这里给大家分享几道比较有意思的笔试题
目录
一、笔试题1:
二、笔试题2
三、笔试题3:
四、笔试题4:
五、笔试题5:
编辑
六、笔试题6:
七、笔试题7:
八、笔试题8:
一、笔试题1:
//代码的运行结果是什么?
#include <stdio.h>
int main()
{int a[5] = { 1, 2, 3, 4, 5 };int* ptr = (int*)(&a + 1);printf("%d,%d", *(a + 1), *(ptr - 1));return 0;
}解析:
这是一段比较简单的代码,关于上面的代码,可以分析一下,a是一个整形数组,里面有五个元素,ptr是一个整形指针,&a+1表示的是跳过一个a数组,类型是一个数组指针的类型,所以要强制转换为整形指针才可以存放在ptr中,所以ptr指向的就是a数组后面的那个地址。

*(a+1)中的a表示数组首元素的地址,+1表示跳过一个整形,指向数组的第二个元素的地址,然后解引用,得到数组的第二个元素,所以*(a+1)的结果是2
*(ptr-1)中的ptr是一个整形指针,指向的是a数组后面的地址,-1表示向前移动1个整形,所以指向了数组的最后一个元素的地址,然后解引用,得到的就是数组的最后一个元素,所以*(ptr-1)的结果是5
二、笔试题2
假设p 的值为0x100000。 如下表表达式的值分别为多少?
已知,结构体Test类型的变量大小是20个字节
#include <stdio.h>struct Test
{int Num;char* pcName;short sDate;char cha[2];short sBa[4];
}*p;int main()
{printf("%p\n", p + 0x1);printf("%p\n", (unsigned long)p + 0x1);printf("%p\n", (unsigned int*)p + 0x1);return 0;
}解析:
Test是一个结构体,p是一个结构体指针,已知结构体的大小是20,所以结构体指针在加减整数的时候移动的单位就是20,p的初始值为0x100000,这是一个16进制的数字,以0x开头的为16进制数字
p+0x1中的p指向的是结构体,+1表示跳过一个结构体,由已知结构体的大小是20,所以p由起始的0x100000要加上20,20的16进制就是0x14,所以p+0x1的结果是0x100014
(unsigned long)p+0x1表示先把p强制类型转化为无符号长整形然后再加1,既然是整形那就相当于整数,整数加1就只是单纯的加1,所以(unsigned long)p+0x1的结果是0x100001
(unsigned int*) p + 0x1表示先把p强制类型转化为无符号的整形指针,既然是整形指针,加减整数表示跳过整形个单位,所以(unsigned int*)p + 0x1的结果是0x100004
三、笔试题3:
//代码运行结果是什么?
#include <stdio.h>int main()
{int a[4] = { 1, 2, 3, 4 };int* ptr1 = (int*)(&a + 1);int* ptr2 = (int*)((int)a + 1);printf("%x,%x", ptr1[-1], *ptr2);return 0;
}解析:
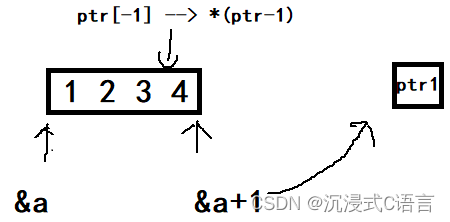
a是一个整形数组,&a+1表示取出整个数组的地址然后地址跳过一个数组,这时它的类型是一个指针数组的类型,强制类型转化为int*用ptr1来接受,ptr[-1]可以写成*(ptr-1),ptr是一个整形指针,-1表示移动一个整形,所以就指向了4这个元素的地址,然后解引用就得到了4
所以ptr[-1]的结果是4
a表示数组首元素的地址,然后将其强制类型转化为int类型,然后+1就表示单纯的加1,如果这时a的地址是0x0012ff40,那么+1之后的结果就变成了0x0012ff41,也就是说地址移动了一个字节,然后再将其强制类型转化为int*用ptr2来接收,如果机器是小端存储模式,那么a数组在内存中存储的方式就是01 00 00 00 02 00 00 00 03 00 00 00 04 00 00 00,移动一个字节之后的地址就变成了00 00 00 02 00 00 00 03 00 00 00 04 00 00 00,又因为ptr2是整形指针,解引用向后面访问4个字节,所以就得到了00 00 00 02,这个值在小端的存储模式下表示的值是 02 00 00 00,所以*ptr2的结果是2000000

四、笔试题4:
//代码运行结果是什么?
#include <stdio.h>int main()
{int a[3][2] = { (0, 1), (2, 3), (4, 5) };int* p;p = a[0];printf("%d", p[0]);return 0;
}
解析:
如果仔细观察这个二维数组,可以发现它其实只有三个元素:1 3 5,而并非0 1 2 3 4 5,为什么呢?可以发现在{}里面用()分隔的元素,其实在()里面是一个逗号表达式,逗号表达式的结果是最后一个表达式的结果,所以(0,1)的结果是1,(2,3)的结果是3,(4,5)的结果是5,所以二维数组里面第一行的元素就是1,3,5,a[0]表示第一行的地址,将其存放在p里面,p[0]表示的就是第一行中下标为0的元素,所以p[0]的结果是1
五、笔试题5:
//代码运行结果
#include <stdio.h>int main()
{int a[5][5];int(*p)[4];p = a;printf("%p,%d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]);return 0;
}解析:
指针-指针得到的是两个指针之间的元素个数
%p在打印的时候是直接将内存里面的值进行打印
int(*p)[4]表示的是一个数组指针,p指向的是一个整形指针,里面有四个元素,也就是意味着p+1只能跳过4个字节
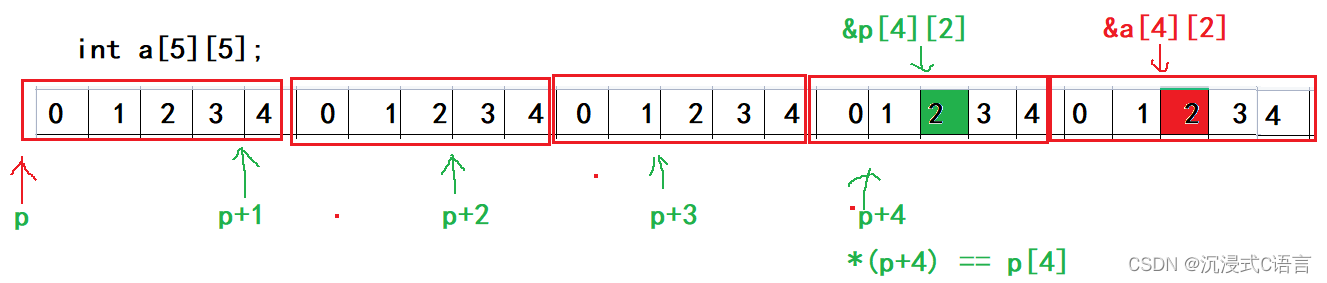
通过图来看&p[4][2]是低地址,而&a[4][2]是高地址,所以&p[4][2] - &a[4][2] = -4,-4如果使用%d的形式来打印就是-4,但是如果是以%p的形式来打印就得计算了:
-4的原码:10000000000000000000000000000100
-4的反码:1111111111111111111111111111111111011
-4的补码:1111111111111111111111111111111111100
所以在以%p的形式来打印-4时会打印-4的补码,四位的1是一个F,所以-4的补码转化为16进制就是FFFFFFFC,所以&p[4][2] - &a[4][2], &p[4][2] - &a[4][2]的结果分别为FFFFFFFC和-4
六、笔试题6:
#include <stdio.h>int main()
{int aa[2][5] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };int* ptr1 = (int*)(&aa + 1);int* ptr2 = (int*)(*(aa + 1));printf("%d,%d", *(ptr1 - 1), *(ptr2 - 1));return 0;
}解析:
&aa拿到aa二维数组的整个地址,+1跳过整个数组,然后强制类型转化为int*的指针赋给ptr1,所以*(ptr1 - 1)的结果是10
aa表示二维数组第一行的地址,+1表示跳过一行,指向了第二行,然后解引用拿到了第二行的元素,再进行强制类型转化为int*的指针赋给ptr2,所以ptr2指向的就是数组第二行的起始地址,所以*(ptr2 - 1)的结果是5
七、笔试题7:
#include <stdio.h>int main()
{char* a[] = { "work","at","alibaba" };char** pa = a;pa++;printf("%s\n", *pa);return 0;
}解析:
以前提到过一个常量字符串放进指针里面的时候存放的是它的首字符的地址,所以a这个指针数组里面存放的是w、a、a的地址,然后使用一个二级指针来接收a,在这里的a表示数组首元素的地址,也就是w的地址,pa++跳过一个字符指向了a,然后*pa得到的就是a字符往后的元素,所以*pa的结果是at
八、笔试题8:
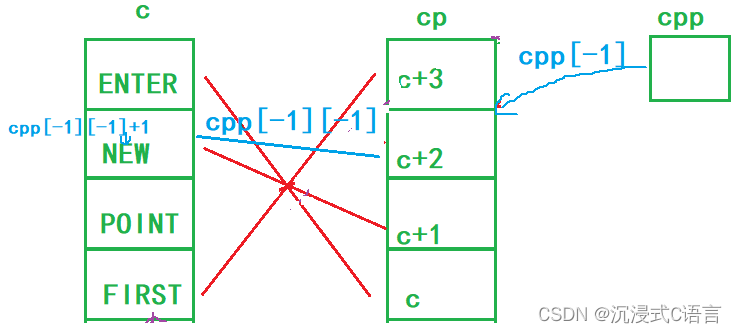
//代码的运行结果是什么?#include <stdio.h>
int main()
{char* c[] = { "ENTER","NEW","POINT","FIRST" };char** cp[] = { c + 3,c + 2,c + 1,c };char*** cpp = cp;printf("%s\n", **++cpp);printf("%s\n", *-- * ++cpp + 3);printf("%s\n", *cpp[-2] + 3);printf("%s\n", cpp[-1][-1] + 1);return 0;
}解析:
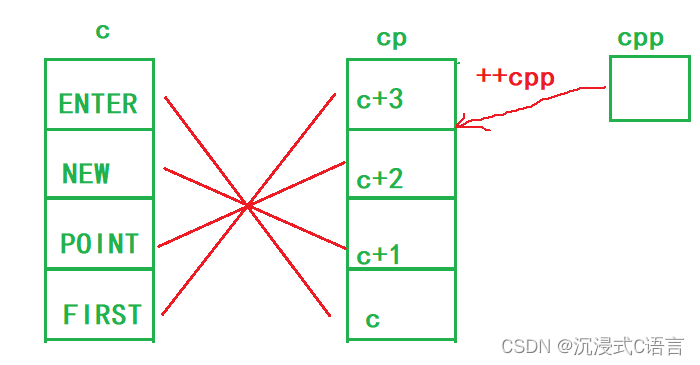
printf("%s\n", **++cpp);
++cpp是前置++,先++后使用,所以cpp指向了POINT,所以**++cpp的结果是POINT
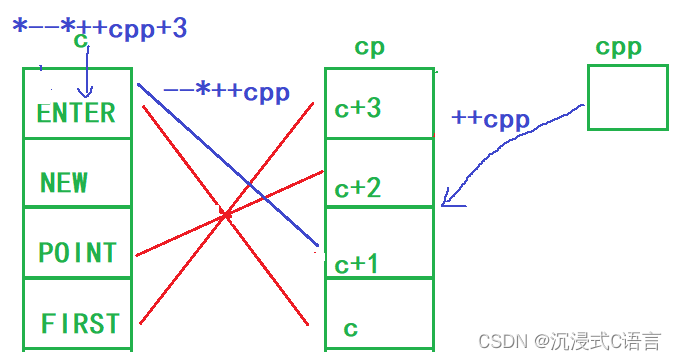
printf("%s\n", *-- * ++cpp + 3);
这时的cpp指向的是c+2的地址,++cpp指向了c+1的地址,然后*++cpp得到了c+1的这块空间,c+1指向的是NEW,然后--,表示c+1的这块空间--,所以c+1指向的就变成了ENTER,然后再解引用拿到的是ENTER这个字符串,再+3表示ENTER跳过三个字节指向了ER,所以*-- * ++cpp + 3的结果是ER
printf("%s\n", *cpp[-2] + 3);
这时的cpp指向的是c+1的地址,*(cpp - 2) = cpp[-2],所以cpp指向的是c+3的地址,然后解引用拿到了这块空间,这块空间里面存放的是FIRST,然后+3FIRST跳过三个字节,所以*cpp[-2] + 3的结果是ST

printf("%s\n", cpp[-1][-1] + 1);
cpp[-1][-1]可以拆解为*(*(cpp-1)-1),这时的cpp指向的是c+3的地址,-1然后解引用得到的是c+2的这块空间,这块空间指向的是POINT,然后再-1解引用就得到了NEW,再+1跳过一个字节,所以cpp[-1][-1] + 1的结果是EW
程序运行结果为:
POINT
ER
ST
EW
本期分享到此结束,喜欢的老铁留下关注再走吧,万分感谢!