自己做网站用买域名吗win10系统优化软件
一.制作主界面
首先创建一个Java项目命名为puzzlegame
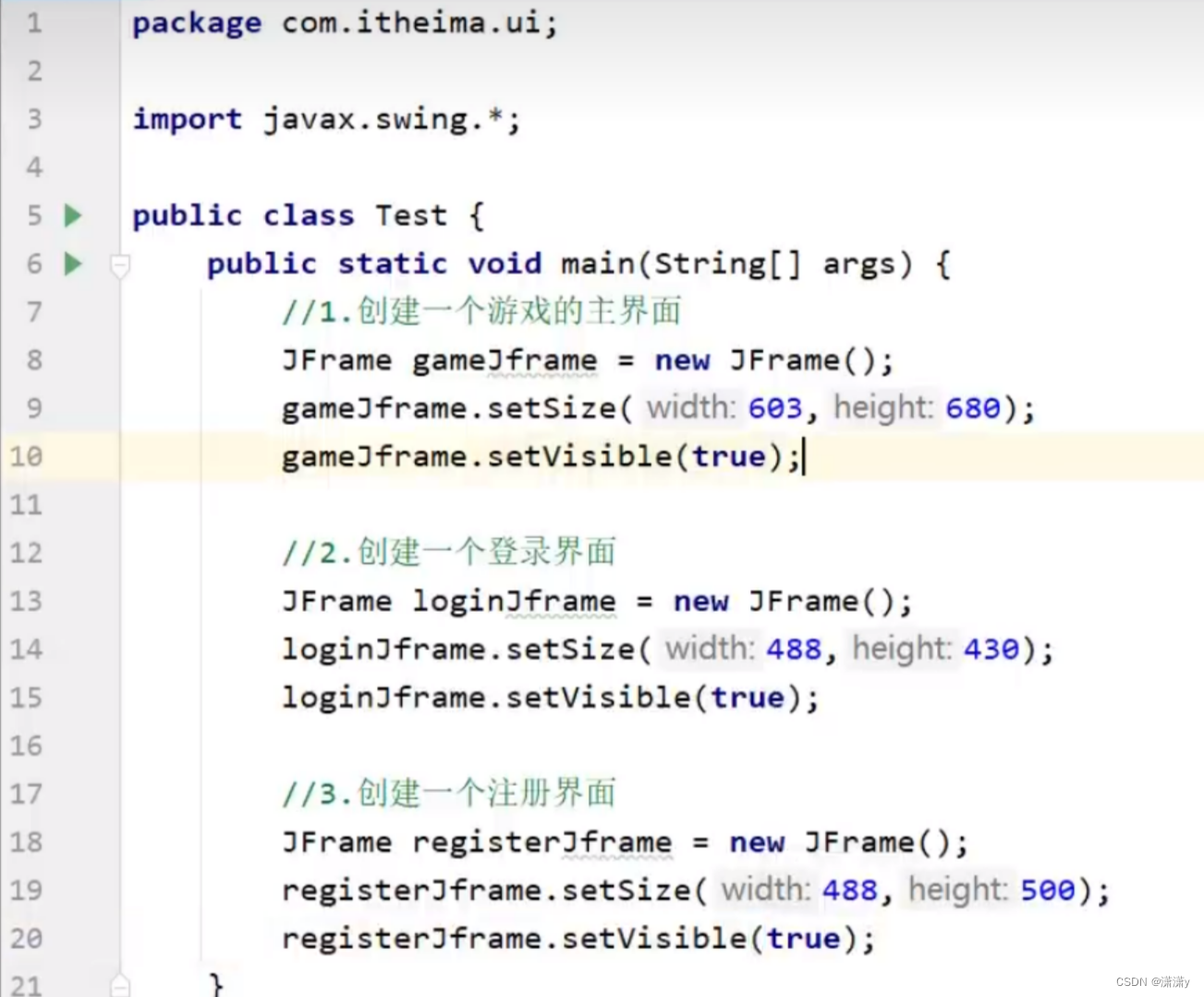
结果:】
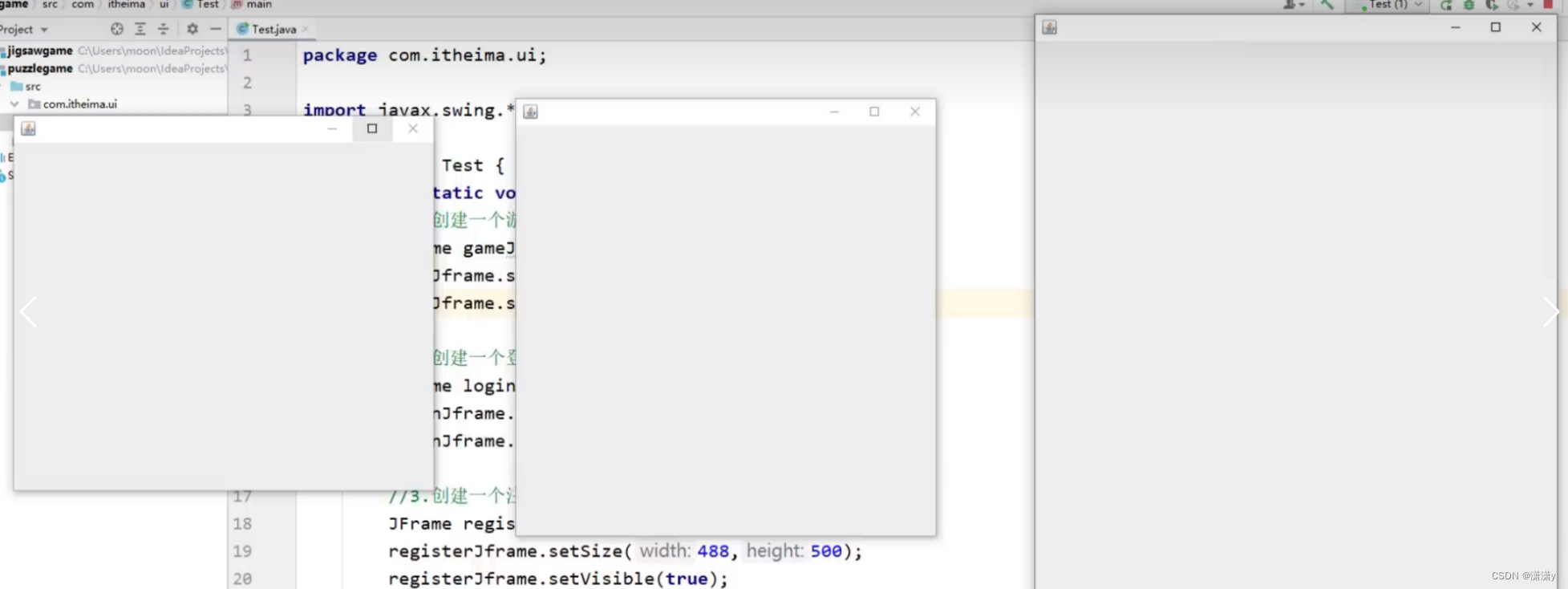
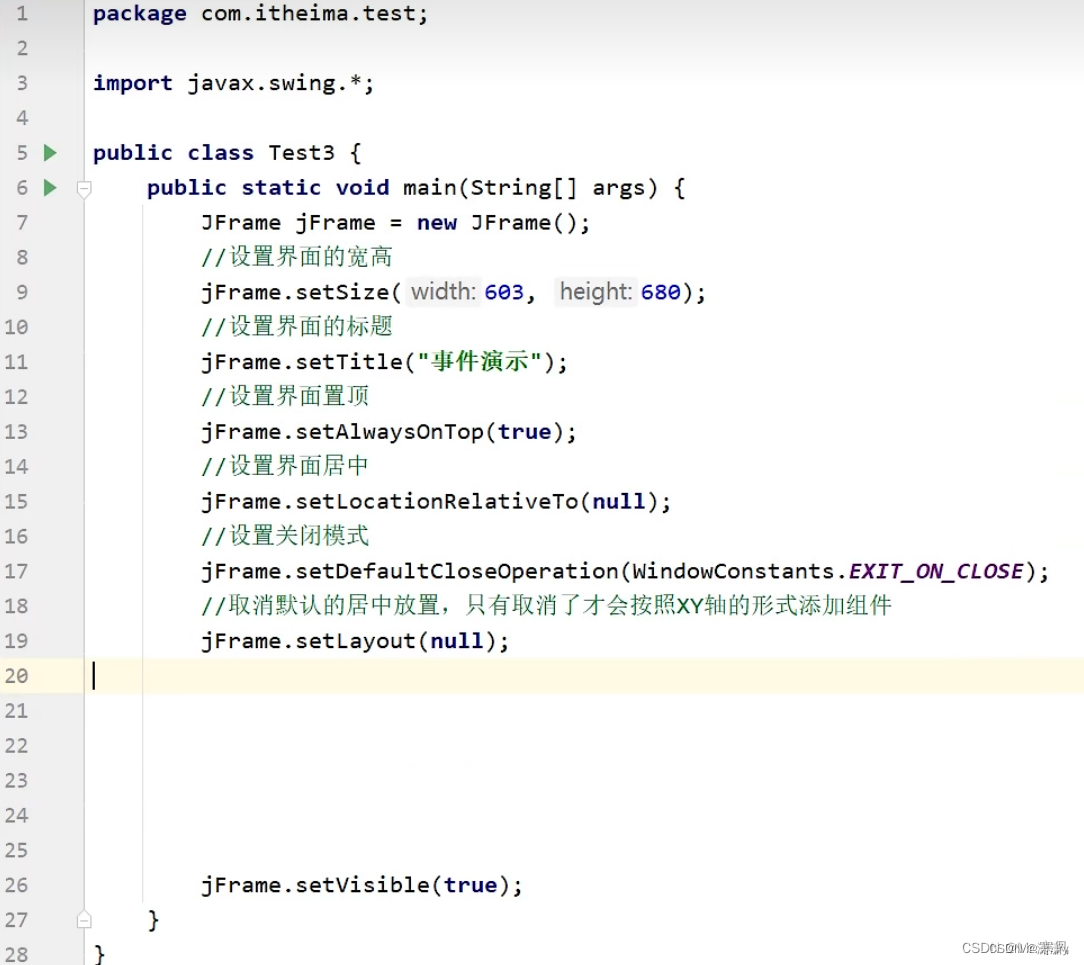
二.设置界面
代码:
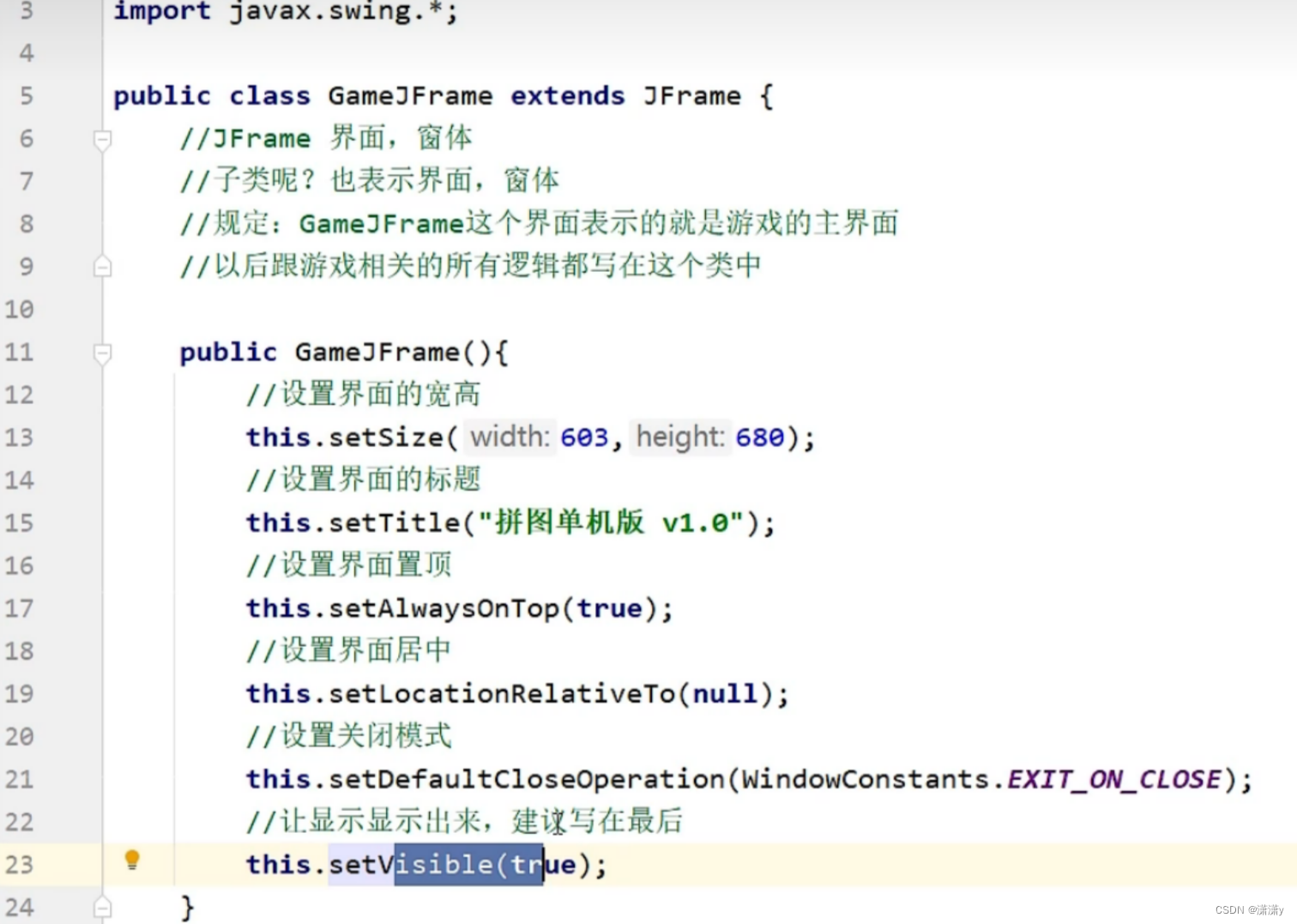
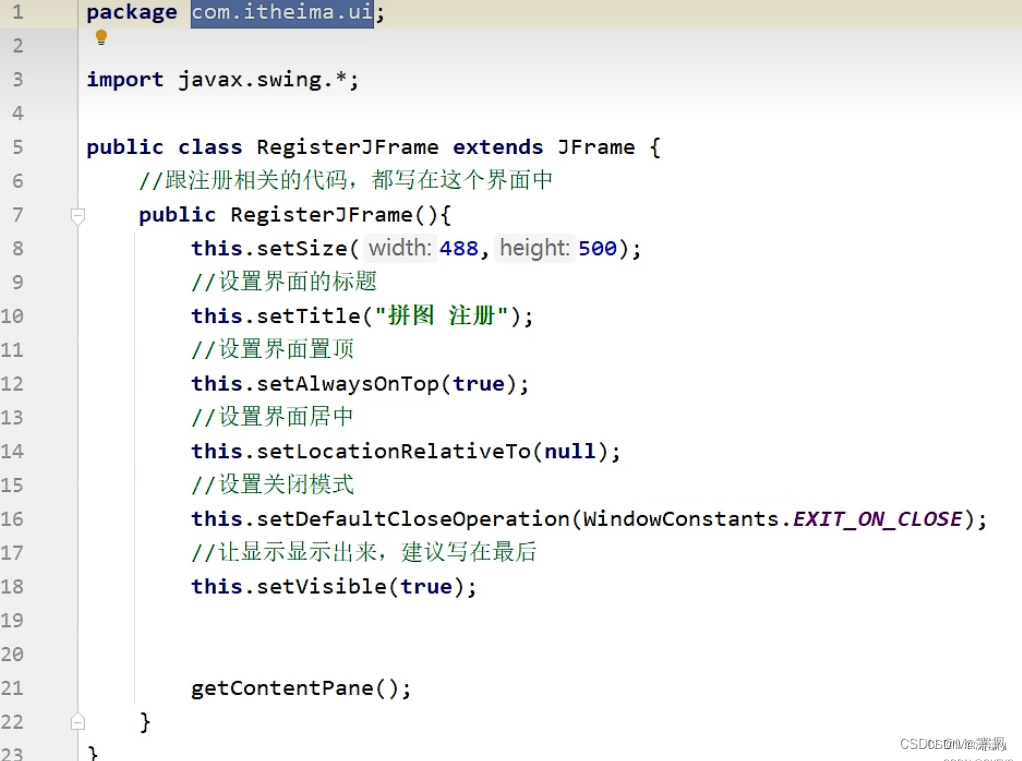
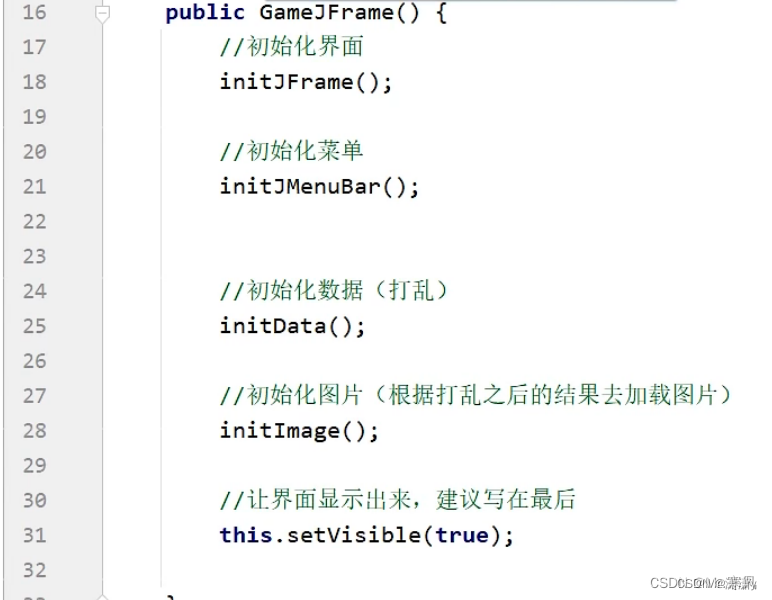
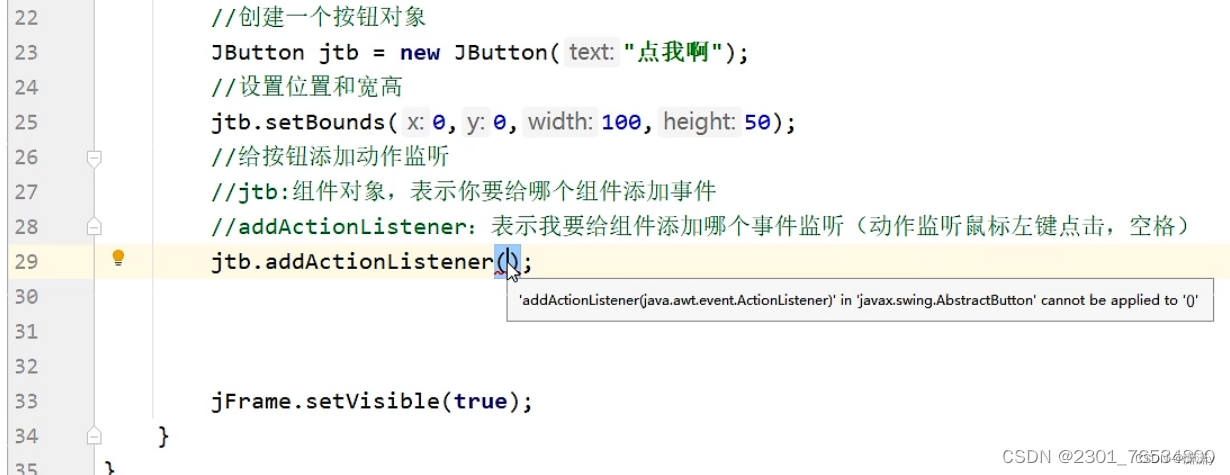
三.初始化界面
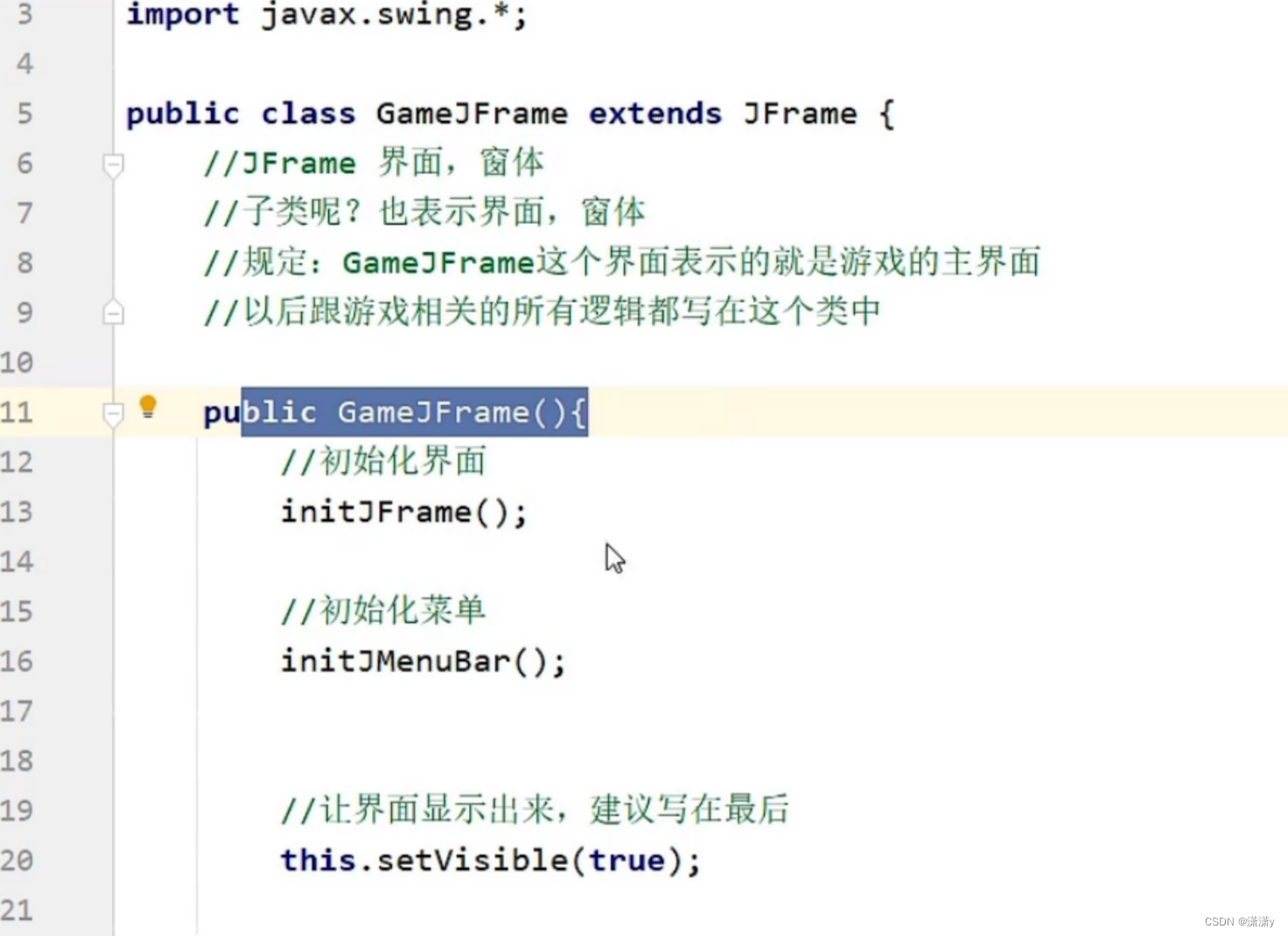
代码:

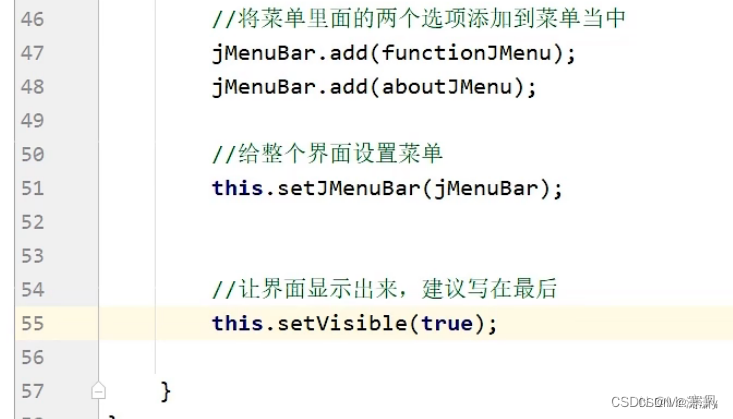
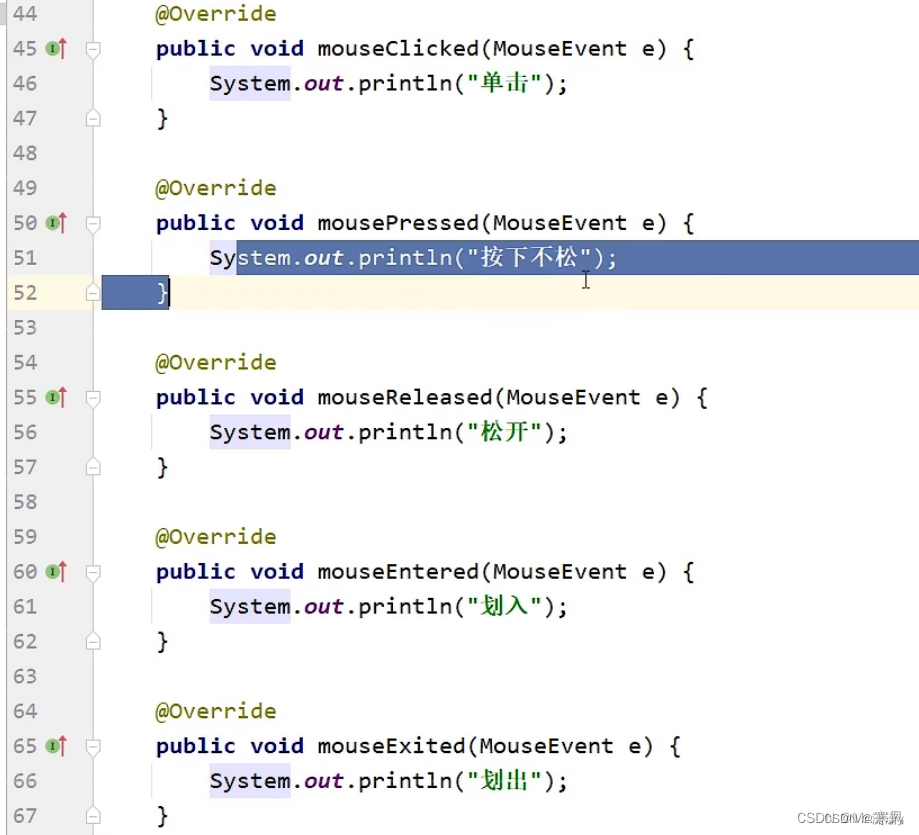
优化代码:
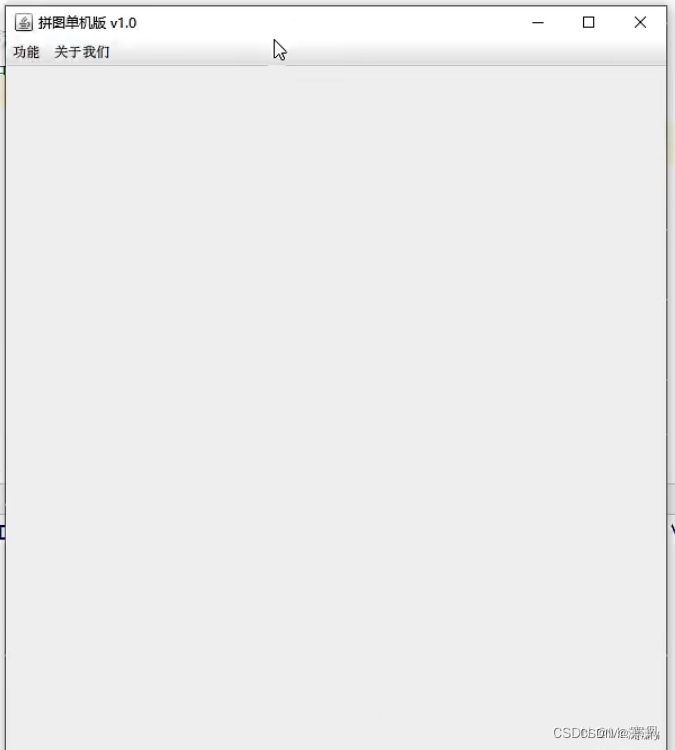
四.添加图片
先在Java项目中创建图片文件夹,将图片导入其中
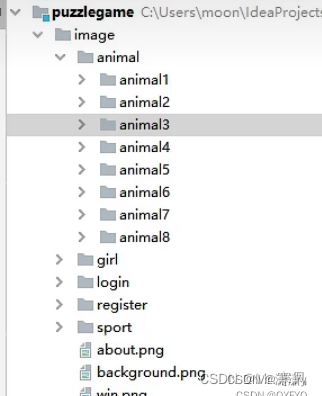
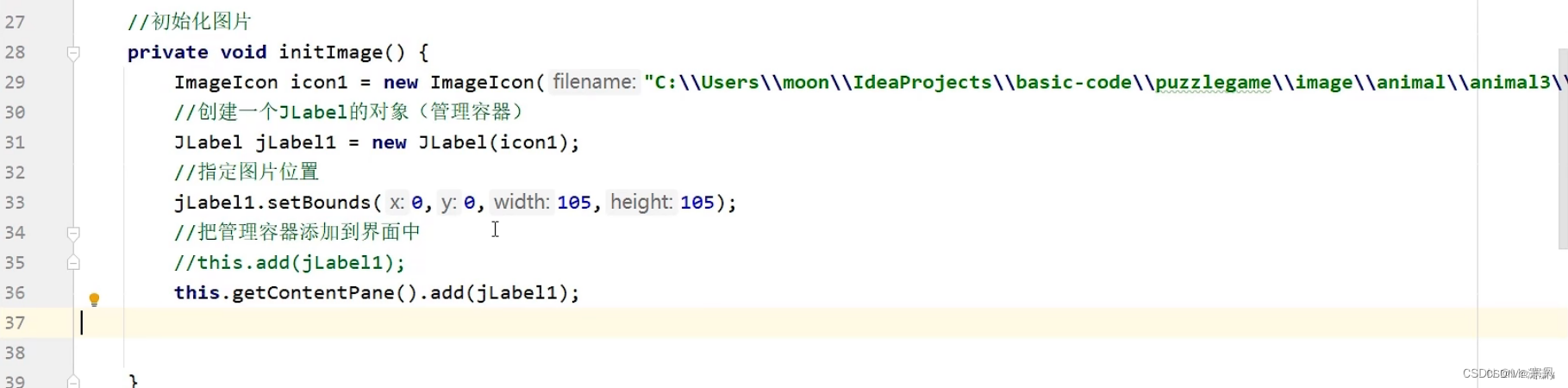
管理图片: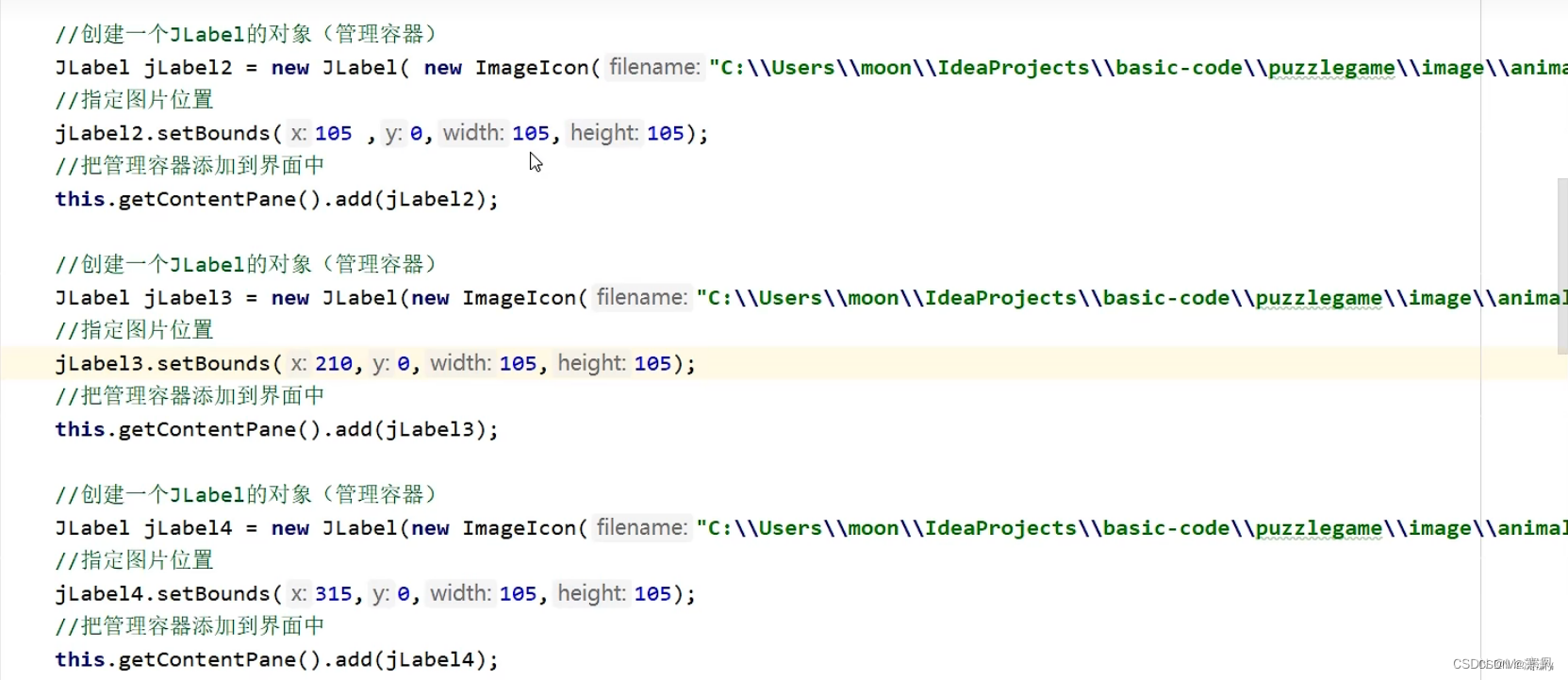

五.打乱图片顺序
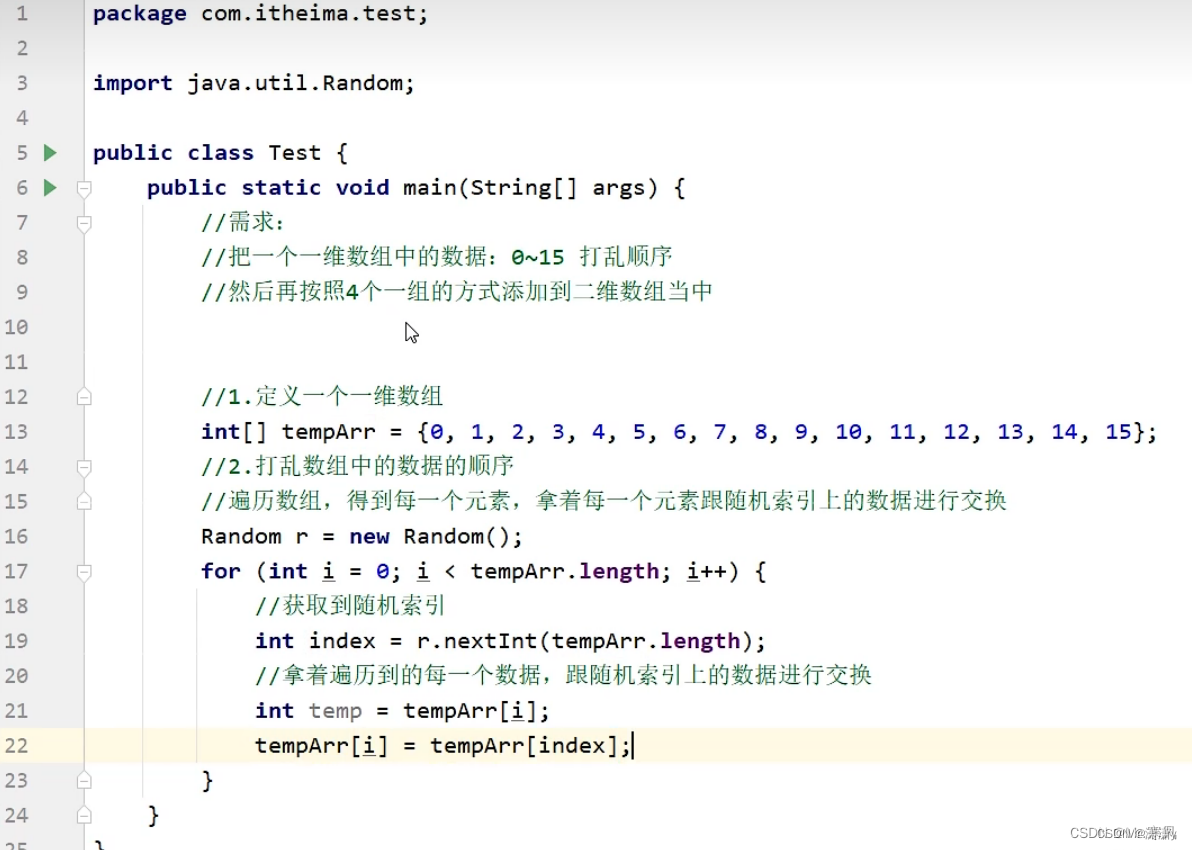




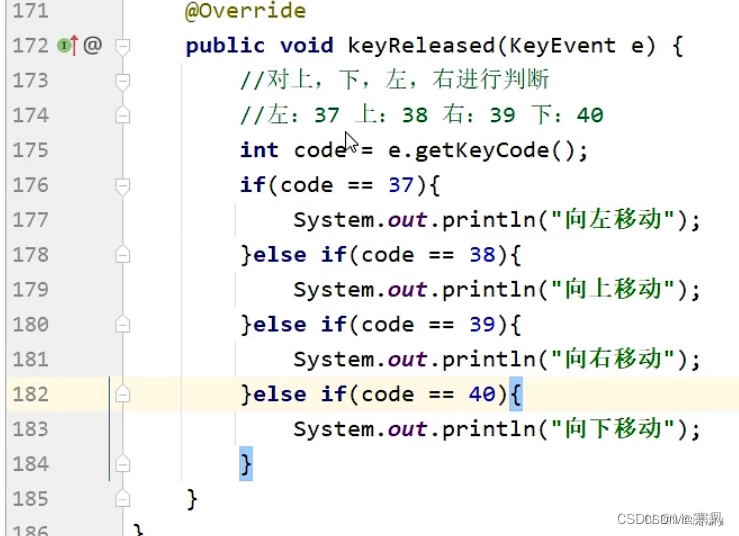
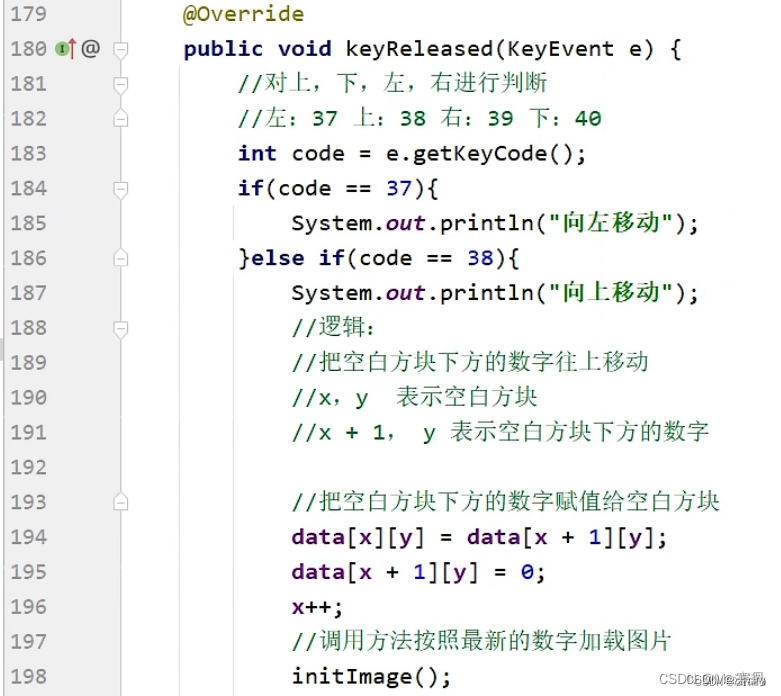

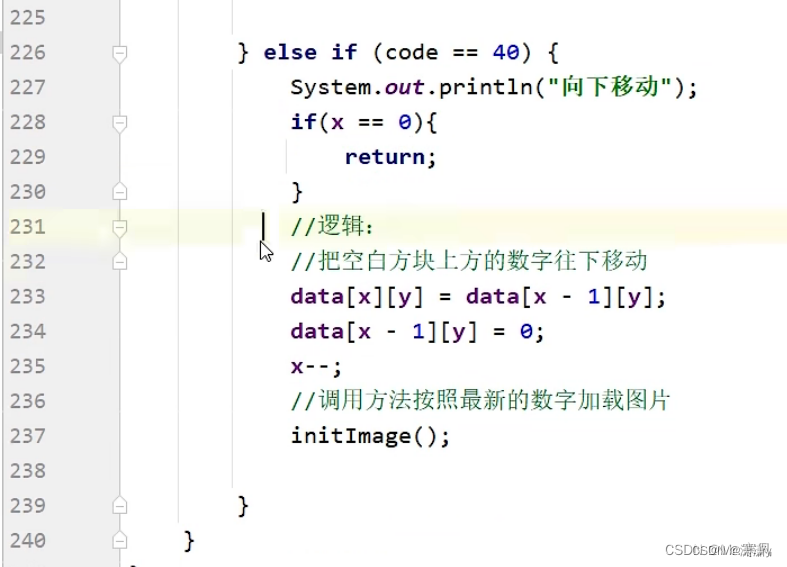


一.制作主界面
首先创建一个Java项目命名为puzzlegame
结果:】
二.设置界面
代码:
三.初始化界面
代码:
优化代码:
四.添加图片
先在Java项目中创建图片文件夹,将图片导入其中
管理图片:
五.打乱图片顺序