扶风做网站怎么做网上销售
一、效果展示

二、基于vite配置
1.首先安装react-monaco-editor和monaco-editor包
npm add react-monaco-editornpm i monaco-editor2.其次创建一个单独的文件(此处是tsx、直接用app或者jsx也行)
import { useState, useEffect } from 'react'
import MonacoEditor from 'react-monaco-editor'
import './worker'type Props = {jsonCode: any
}const editor: React.FC<Props> = (props) => {//配置项const options = {readOnly:true,selectOnLineNumbers:true,matchBrackets:'near' as const}//json代码const [jsonCode, setJsonCode] = useState('{}')//渲染获取到的json代码useEffect(() => {if (props.jsonCode) {setJsonCode(JSON.stringify(JSON.parse(props.jsonCode), null, 2))}}, [props.jsonCode])//改变代码时触发const handleJsonCodeChange = (e: any) => {setJsonCode(e)console.log(jsonCode,'jsoncode代码同步')}return (<><h2>真实数据(开发人员可以直接编辑)</h2><MonacoEditorwidth="100%"height="500"language="json"theme="vs-dark"defaultValue='{}'value={jsonCode}onChange={handleJsonCodeChange}options={options}></MonacoEditor></>)
}export default editor
接下来将此文件作为组件在其他组件中正常使用即可
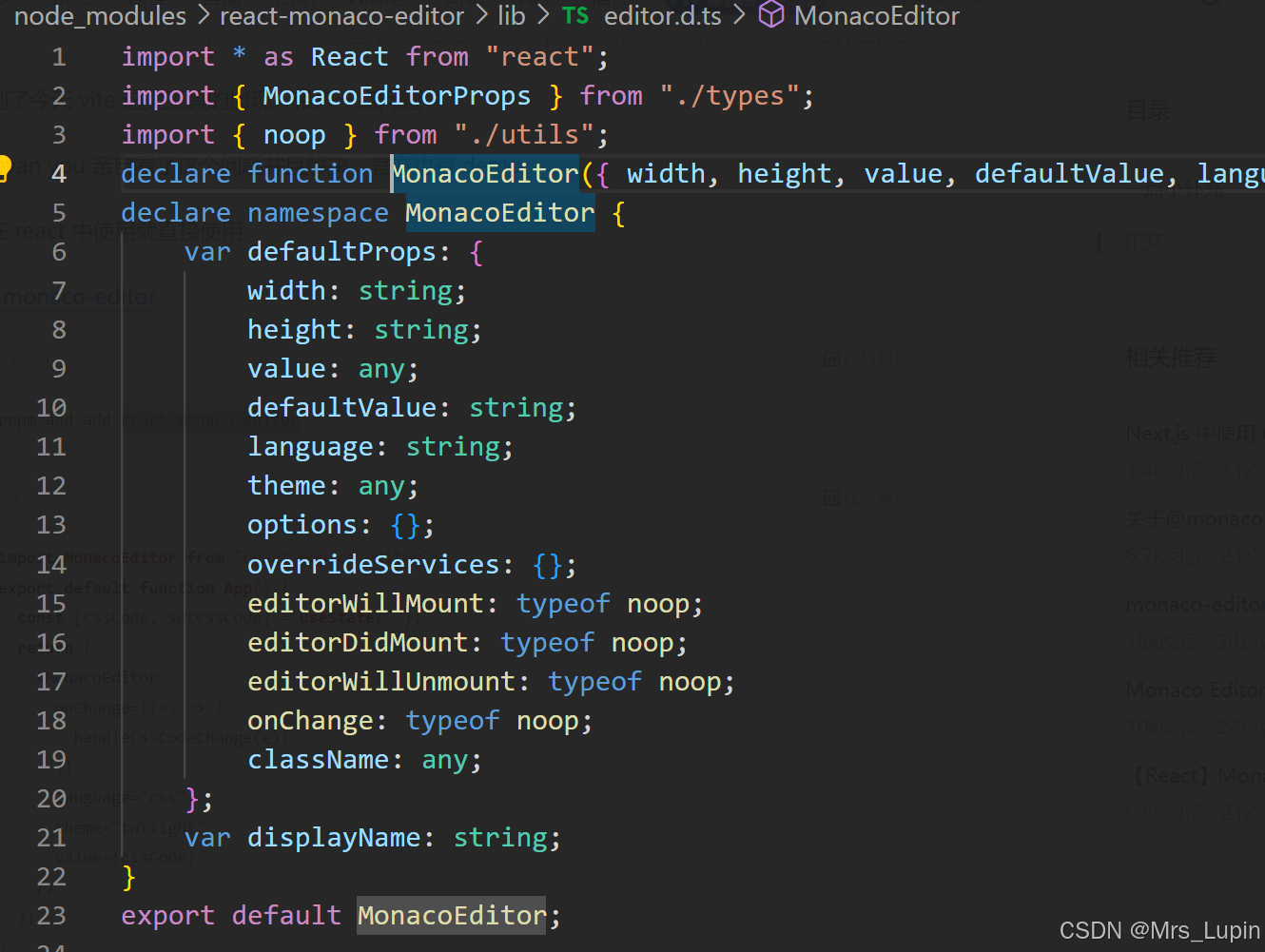
根据MonacoEditor自带的配置项可以看出MonacoEditor还有非常多灵活的用法
3.如何高亮显示代码
import * as monaco from 'monaco-editor'
import editorWorker from 'monaco-editor/esm/vs/editor/editor.worker?worker'
import jsonWorker from 'monaco-editor/esm/vs/language/json/json.worker?worker'
// import cssWorker from "monaco-editor/esm/vs/language/css/css.worker?worker"
// import htmlWorker from "monaco-editor/esm/vs/language/html/html.worker?worker"
// import tsWorker from "monaco-editor/esm/vs/language/typescript/ts.worker?worker"self.MonacoEnvironment = {getWorker(_, label) {if (label === 'json') {return new jsonWorker()}// if (label === "css" || label === "scss" || label === "less") {// return new cssWorker()// }// if (label === "html" || label === "handlebars" || label === "razor") {// return new htmlWorker()// }// if (label === "typescript" || label === "javascript") {// return new tsWorker()// }return new editorWorker()}
}monaco.languages.typescript.typescriptDefaults.setEagerModelSync(true)
上方代码就是我 MonacoEditor组件中的worker.ts代码,直接引入到MonacoEditor组件中即可
三、官方文档中配置方式
react-monaco-editor的官方文档:
https://github.com/react-monaco-editor/react-monaco-editor/blob/master/README.md
1.和create-react-app结合
首先安装依赖
npm i -D react-monaco-editor react-app-rewired其次将项目中package.json文件中的react-scripts替换为react-app-rewired
最后在项目根目录中创建一个config-overrides.js
const MonacoWebpackPlugin = require('monaco-editor-webpack-plugin');module.exports = function override(config, env) {config.plugins.push(new MonacoWebpackPlugin({languages: ['json']}));return config;
}