木马科技网站建设seo分析seo诊断
title: 免费博客搭建笔记
tags:
- 博客搭建
本次是对自己在网上学习github搭建一个
👇个人免费静态网站的总结当然不是很完美👇
Bow to the new king · iYANG (yangsongl1n.github.io)

接着我会从我的写笔记的个人习惯来逐步介绍如何搭建这个网站
1.写笔记的软件
在下是一名屌丝程序员,不喜欢用word写笔记觉得上面加一些code太麻烦了,用的是Typora 👇
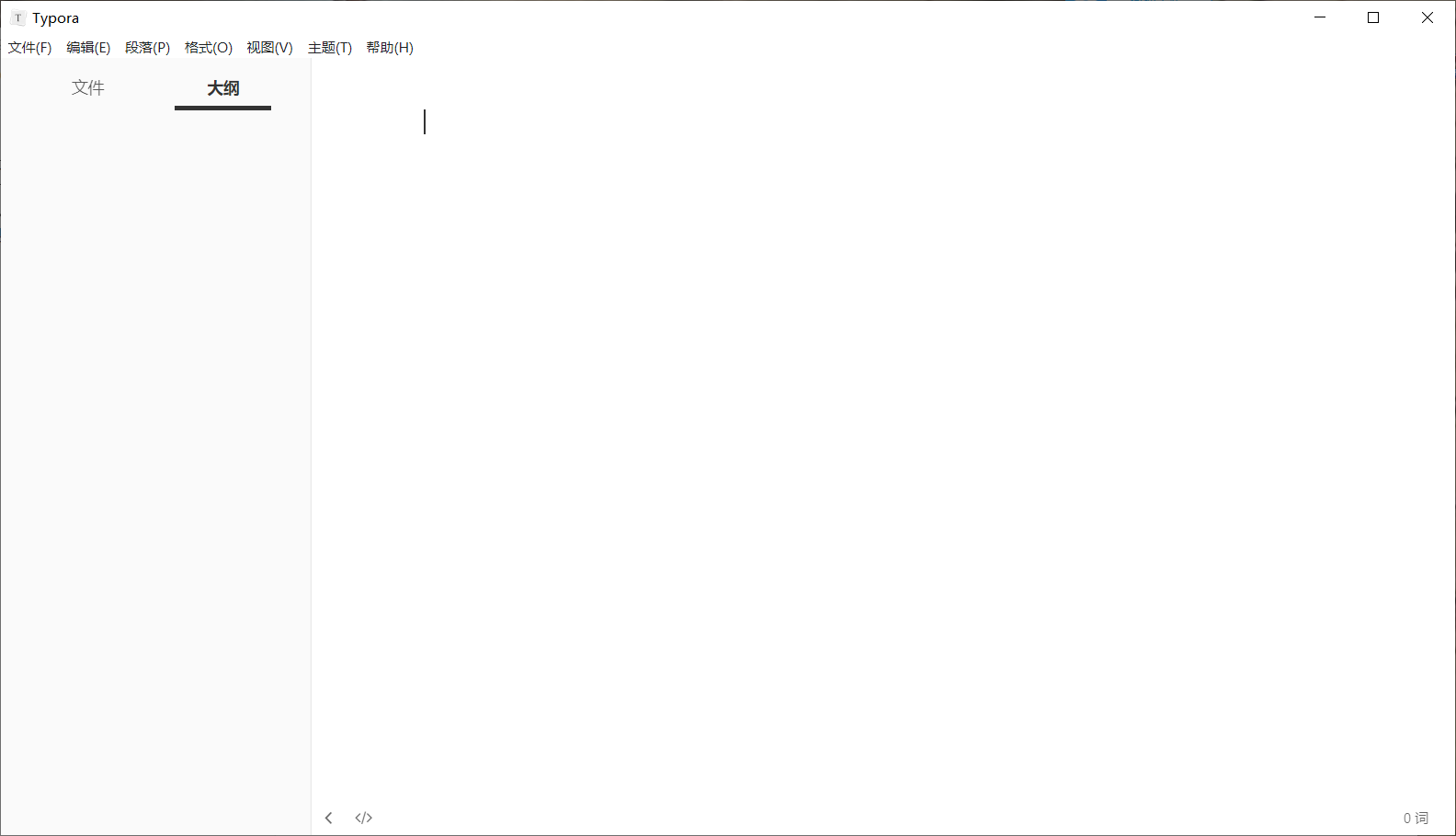
有需要的可以自己去下载,因为搭建的个人博客也是上传Markdown的文件所以用这个还是比较舒服的
Typora 官方中文站 (typoraio.cn)

进击:关于如何用鼠标右键新建Typora文档
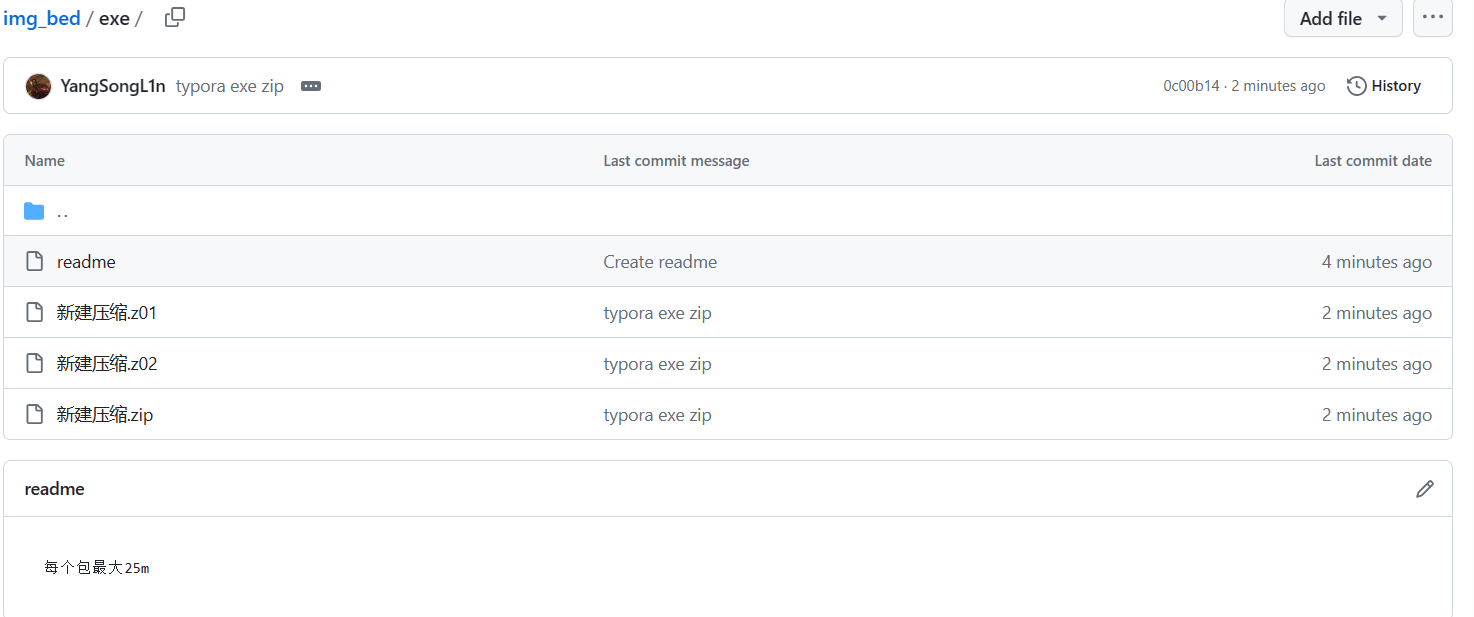
这是要钱的之前有免费的坂本大家可以去网上找找,或者来我这下载:
img_bed/exe at main · YangSongL1n/img_bed (github.com)
2.写笔记的图床配置
有些人不喜欢写这md的时候图片默认保存到本地觉得反正是一些无关紧要的图片放在哪不是放
遂推出图床搭建的方法配合写笔记使用下载与配置大家可以参考下面这篇文章👇
使用Github+picGo搭建图床,超详细教程 (cbww.cn)
3.关于静态网页
Jekyll Theme Wuk · wu-kan
跟着一步步走就可以配置成功了
4.如何更新文章
文件名命名需要

我的就是这样
然后就是抬头

---
title: 免费博客搭建笔记
tags:- 博客搭建
---
title 就是你的文章名字 tags 就是 话题
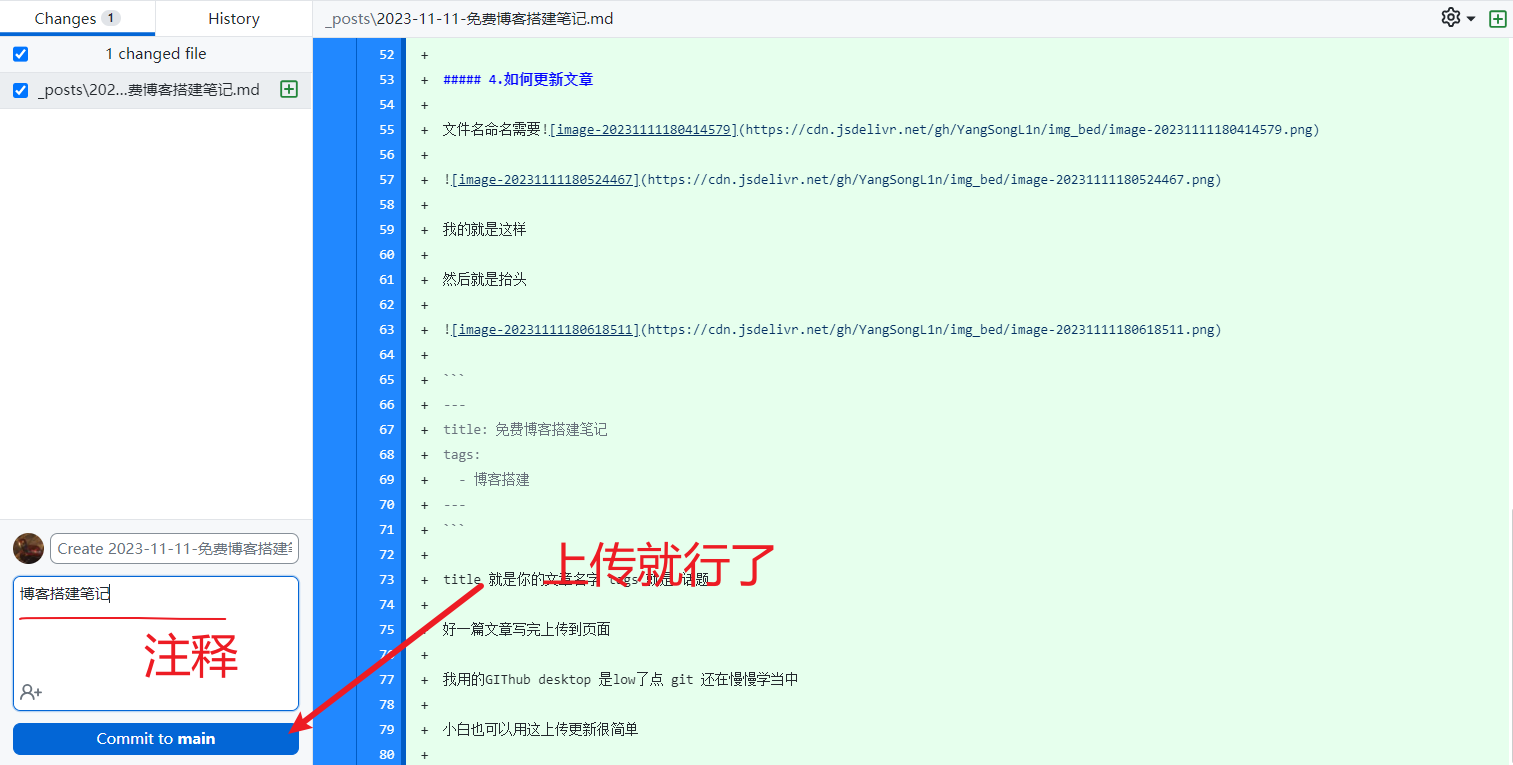
好一篇文章写完上传到页面
我用的GIThub desktop 是low了点 git 还在慢慢学当中
小白也可以用这上传更新很简单
拖到里面然后打开软件就可以了
而且以后要是想修改文章了也是这种办法上传
5.下面是出现的一些软件的安装包汇总链接我还是放百度网盘里面吧:
链接:https://pan.baidu.com/s/1h4lPcrOXHT-bf2N-X-xpuQ?pwd=YANG
提取码:YANG
汇总链接我还是放百度网盘里面吧:
链接:https://pan.baidu.com/s/1h4lPcrOXHT-bf2N-X-xpuQ?pwd=YANG
提取码:YANG
–来自百度网盘超级会员V3的分享