电商平台开发流程越秀seo搜索引擎优化
目录
- 前言
- 1. MySQL ODBC 驱动
- 2. 配置 SQL Server 链接服务器
- 3. 彩蛋
前言
此处配置以及安装没有什么理论知识
所以直奔主题,跟着以下步骤配置安装即可
需求:准备在10.197.0.110中链接外部的10.197.0.96的mysql数据源
已默认在10.197.0.96中安装了MySQL数据库并且知道其连接信息(如服务器地址、数据库名称、用户名和密码):mysql官网
1. MySQL ODBC 驱动
需要再外部的10.197.0.110中配置ODBC驱动
(此处不需要安装mysql数据库,只需配置驱动即可)
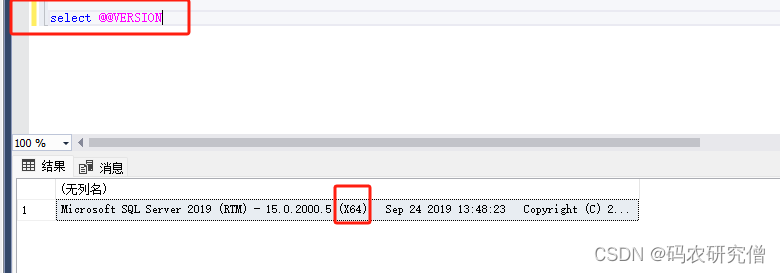
具体安装的电脑位数可通过对方数据库的资源查询版本:select @@VERSION
或者登录远程电脑查询配置
随后下载并安装 MySQL ODBC 驱动程序(MySQL Connector/ODBC):数据源下载
安装完成后,打开ODBC