有没有个人做网站的山东网站seo推广优化价格
🌈🌈🌈关于java
⚡⚡⚡java的由来
我们这篇文章主要是来介绍javaEE,一般称为java企业版,实际上java的历史可以追溯到上个世纪90年代,当时主要的语言主流的还是C语言和C++,但是在那个时期嵌入式初步发展,刚开始是打算制造一个“智能面包机”的,于是专门对此研发出了一种新的语言-Oak(橡树)。

说来也很有意思,当时我们的java创始人詹姆斯.高斯林,起这个名字仅仅是因为当时的办公室透过窗户可以看到一颗橡树,后来这个项目并没有推行下去,但是这门语言发展的不错,后来互联网开始发展,当时最大的浏览器网景公司的netscape,也想要将网页和用户之间有跟多的互动,所以高斯林就把这门语言做了一定完善,并更名为java~~

⚡⚡⚡出师未捷身先死
不久,微软,也推出了自己的浏览器IE,由于当时Windows已经风靡全球,微软将IE和Windows捆绑销售,并推出自己的编程语言J++,全面封杀了java,但是有意思的是虽然微软这波操作确实666,但是自己的语言J++,并没有发展的很好,侧面推动了JavaScript的发展,注意这里的JavaScript和java没有一点关系,起这个名完全就是为了蹭波流量~~,java只好寻求新的出路

创新之路
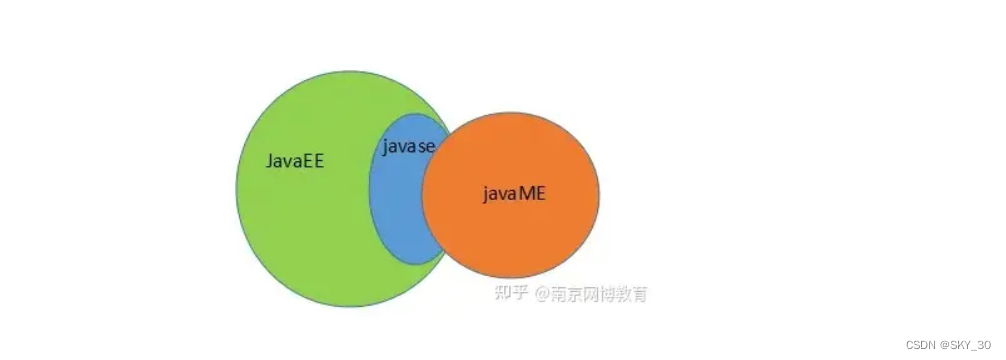
Orcal公司很快推出了一系列的java的新版本,javaSE,javaEE,javaME,分别针对java的日常使用,后端服务器的开发,嵌入式的开发,javaEE是仿照当时大火的语言PHP做的,javaME则是在当时的功能机上面支持安装第三方应用,可以说java一直没有停下创新的脚步~~
⚡⚡⚡再遇波折
随着互联网的信息越来越多,以PHP为主的这类语言,对于越来越庞大的网站,难以适应了~,移动端这边,乔布斯发布了第一部iPhone,标志着移动互联网的发展,之前的那些功能机公司很快倒闭,javaME也被雪藏,java的发展再入低谷。

⚡⚡⚡顿断玉锁走蛟龙
在前端这边,java摒弃了之前的语言,研发出了一个新的霸主 Spring,这其实是以Spring为主的一个大的框架,非常擅长大网站的开发~~

后端,谷歌推出了自己的一套操作系统,大名顶顶的安卓,说来很巧,刚开始本来是打算用python开发安卓的,恰好谷歌与Python的创始人有些事闹得很不愉快~,于是安卓就是用java作为开发语言,此后大家也都知道安卓发展的有多好了。

于是java一跃成为当时语言的NO.1,直接起飞~

🌈🌈🌈计算机的工作原理
⚡⚡⚡冯诺依曼架构
冯·诺依曼架构是一种经典的计算机体系结构,由冯·诺依曼于1945年提出。它将指令和数据存储在同一个存储器中,并使用同一套总线进行数据传输。在冯·诺依曼架构中,计算机的指令和数据被存储在内存中的同一地址空间中,CPU通过抓取指令和数据来执行程序。这种架构具有程序存储器和数据存储器的明显分离,使得指令和数据可以在存储器和CPU之间自由传输。大多数现代计算机系统都采用了冯·诺依曼架构。
哈佛架构是另一种常见的计算机体系结构,最早由哈佛大学提出。在哈佛架构中,指令存储器和数据存储器是物理上分开的,使用不同的总线进行数据传输。指令存储器用于存储程序的指令,数据存储器用于存储程序的数据。哈佛架构的一个优势是可以同时抓取指令和数据,这提高了执行效率。然而,哈佛架构对硬件的要求更高,因为需要独立的指令和数据存储器。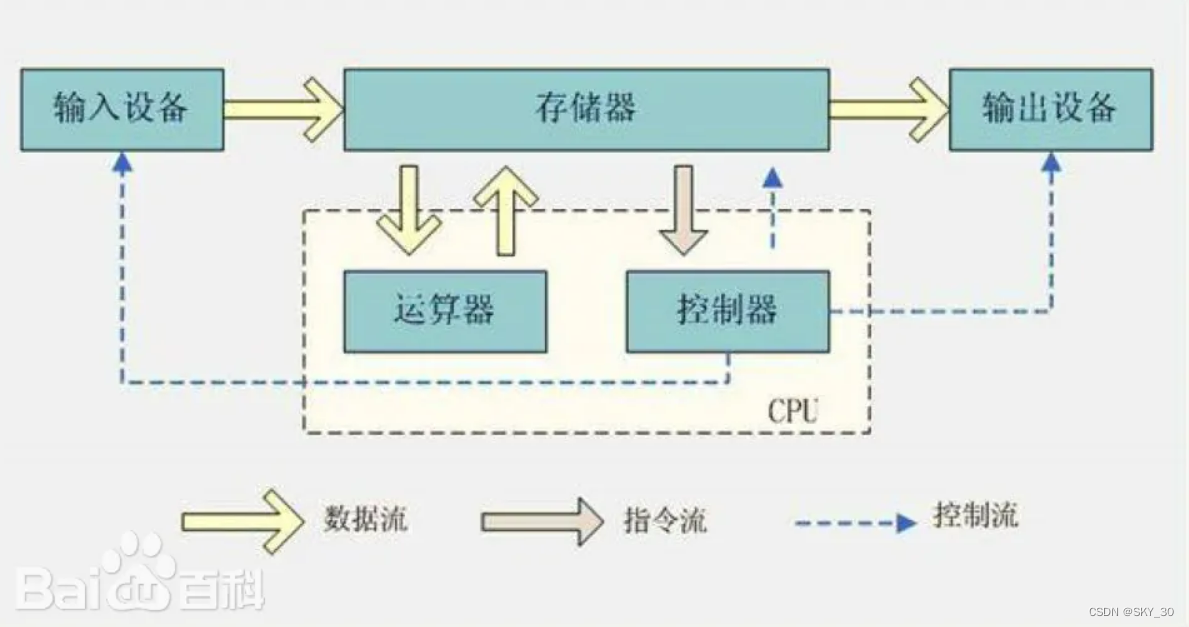
尽管冯·诺依曼架构和哈佛架构在指令和数据存储方式上存在差异,但它们都是用于构建计算机系统的基本原理。现代计算机系统往往会根据具体需求和应用选择适合的架构。
🌈🌈🌈CPU的参数
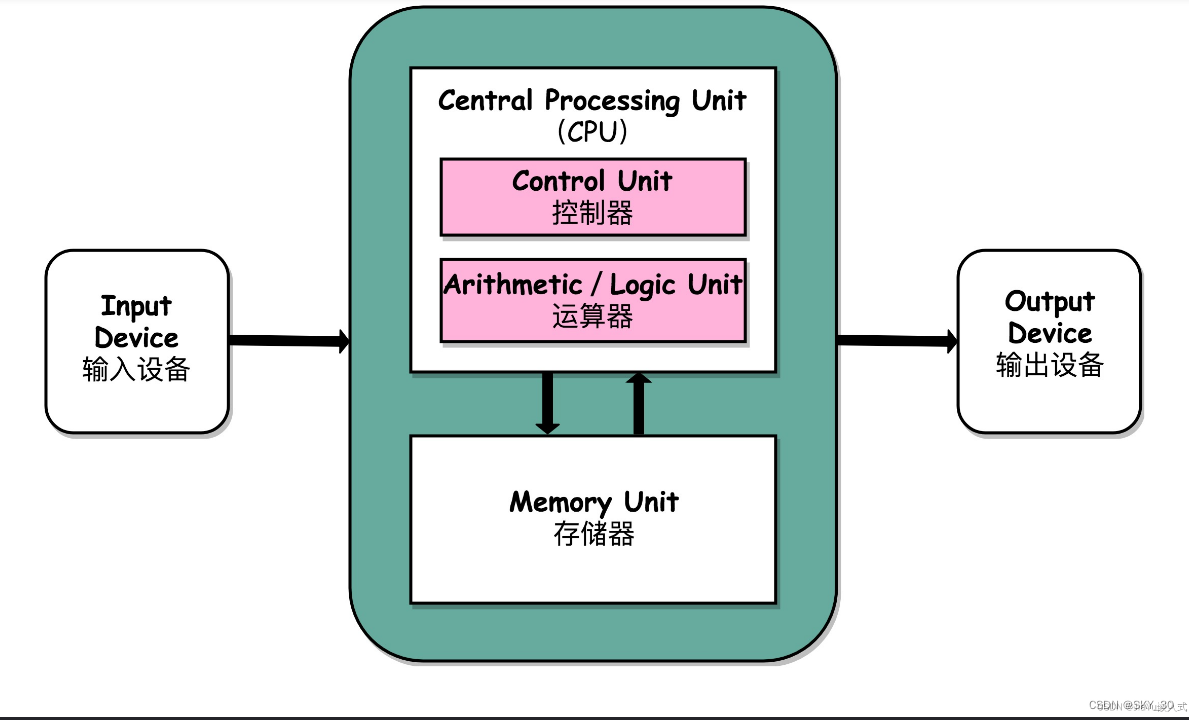
CPU一般由逻辑运算单元、控制单元和存储单元组成。在逻辑运算和控制单元中包括一些寄存器,这些寄存器用于CPU在处理数据过程中数据的暂时保存。一般在市面上购买CPU时所看到的参数一般是以(主频\前端总线\二级缓存)为格式的。例如Intel P6670的就是(2.16GHz\800MHz\2MB)。
⚡⚡⚡核心数
通过任务管理器查看,windows下任务管理器的打开方式较多,比如:
- Win+x,选择任务管理器(T)
- Win+R,输入taskmgr并点击回车键,打开任务管理器
- Ctrl+Alt+Delete,选择任务管理器

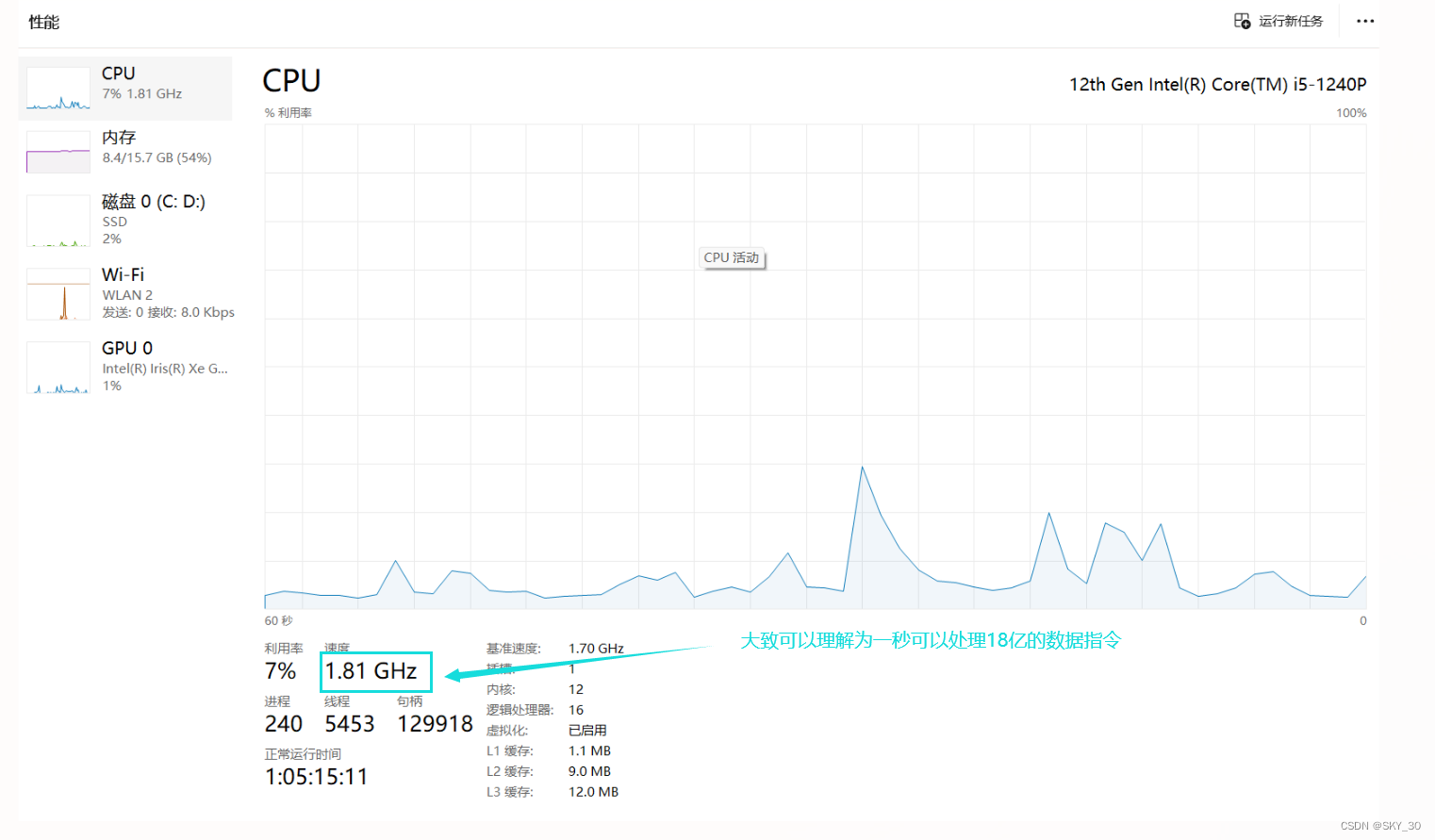
⚡⚡⚡频率
和上面查看核心数的方式一样,在同一个界面:
⚡⚡⚡CPU的寄存器
寄存器是CPU内部用来存放数据的一些小型存储区域,用来暂时存放参与运算的数据和运算结果。其实寄存器就是一种常用的时序逻辑电路,但这种时序逻辑电路只包含存储电路。寄存器的存储电路是由锁存器或触发器构成的,因为一个锁存器或触发器能存储1位二进制数,所以由N个锁存器或触发器可以构成N位寄存器。寄存器是中央处理器内的组成部分。寄存器是有限存储容量的高速存储部件,它们可用来暂存指令、数据和位址。
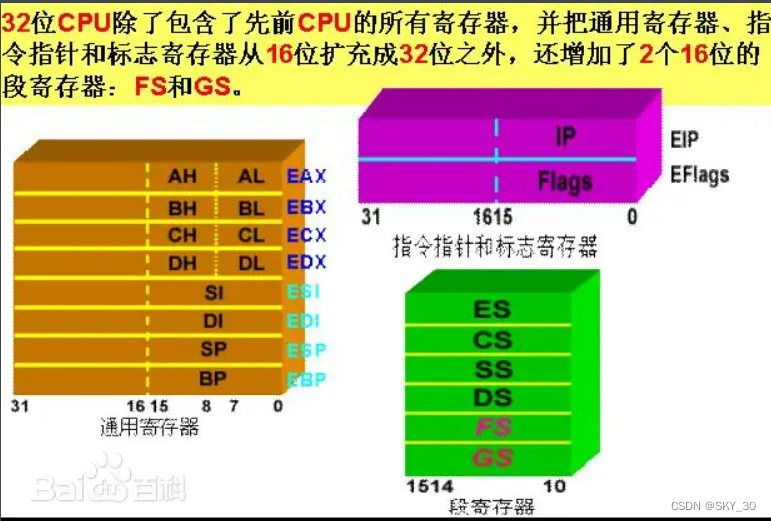
由于寄存器的内存其实是比较小的,有的数据需要不停地从内存读取,这样就会对运行速度有很大的
限制,所以后来计算机引入了缓存的概念,缓存相对来说存储空间就比较大了,且分为三个级别,第一级别访问速度快,存储空间小,后面依次速度变慢,空间变大。
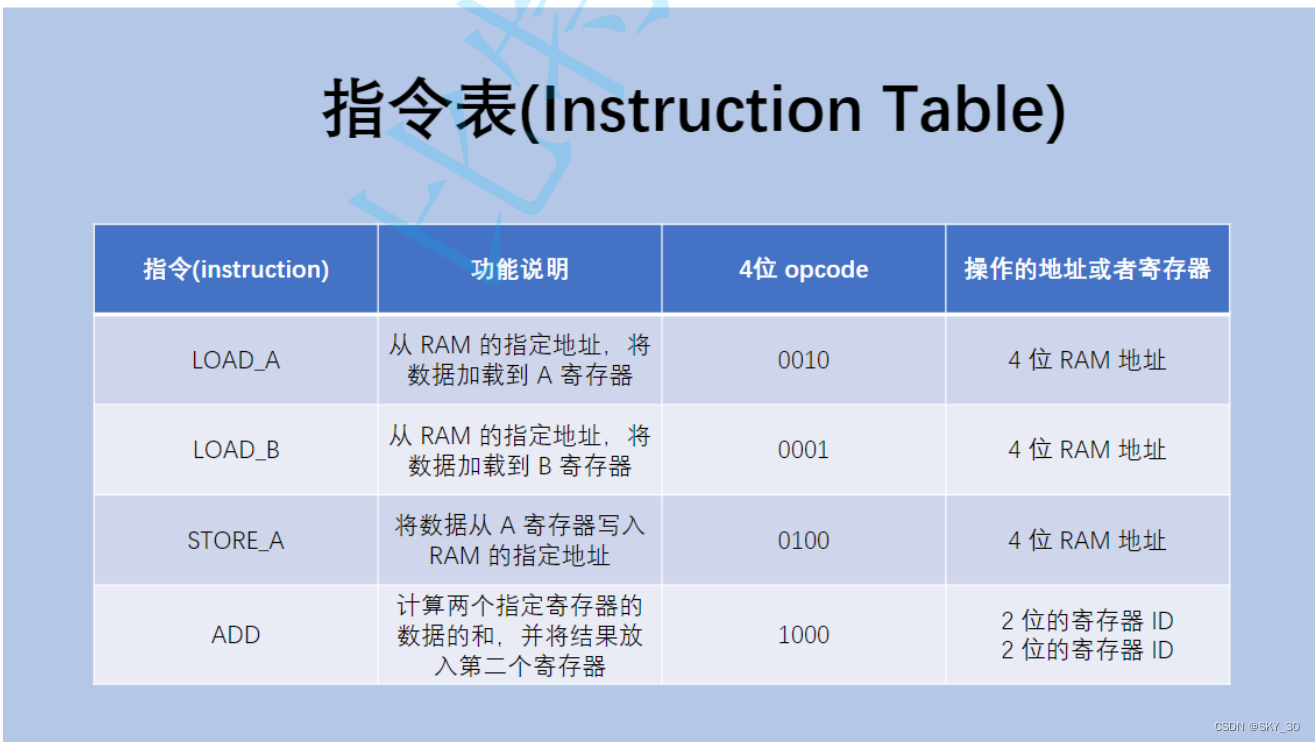
🌈🌈🌈CPU执行指令的过程
一个CPU有哪些指定,在他被造出来的时候,就已经决定了,这里给出一个表格用来说明这个cpu都具有那些指令!!!
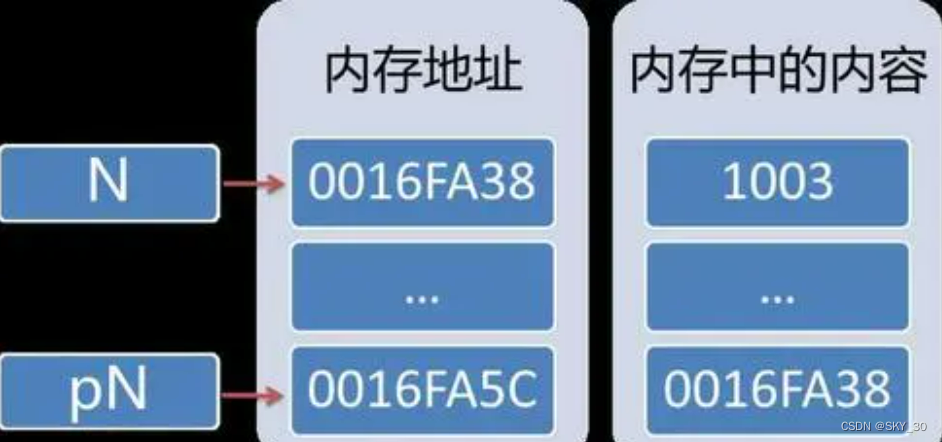
这里给关于内存地址和数据的一张表,来演示CPU指令执行的过程:
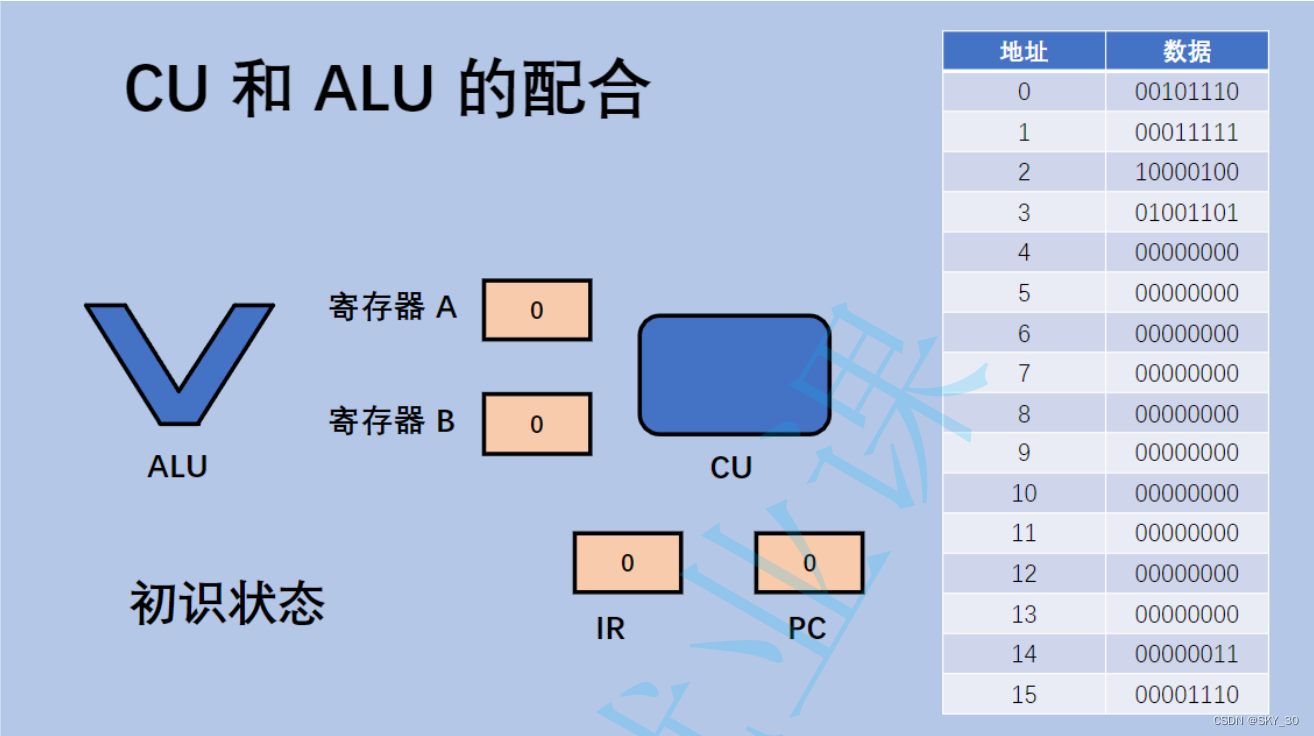
⚡⚡⚡CPU执行的过程可以大致分为三个部分:
- 取指令,CPU从内存中读取到指令内容到CPU的内部
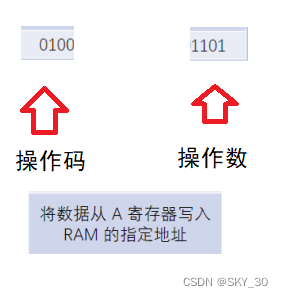
- 解析指令,识别出这个指令到底是干嘛的,以及对应的操作数和操作码。
- 执行指令
CPU中存在一个特殊的寄存器,“程序计数器”,保存了接下来要从内存哪个位置来执行指令~此处就可以默认程序计数器要从哪个内存位置执行指令了。随着指令的执行,程序计数器也会自动++。
⚡⚡⚡CPU执行指令
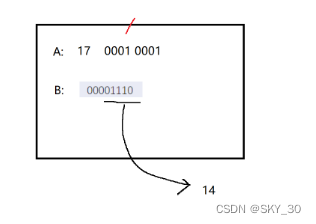
⚡ 1. 读取指令:
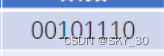
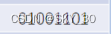
⚡2. 解析指令:
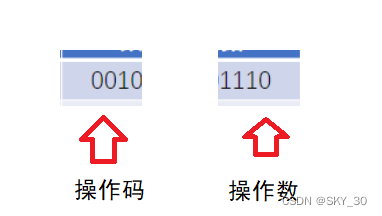
⚡4. 执行指令
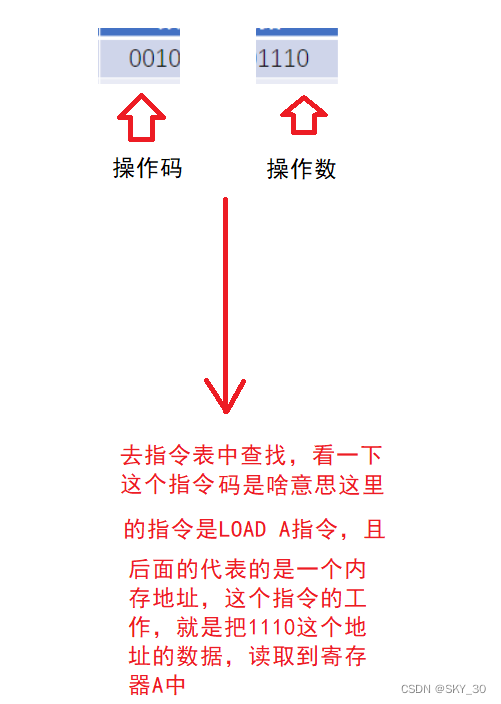
这个1110可以转化成十进制14,也就是把14存储到寄存器当中。
⚡1. 读取指令

⚡2. 解析指令
这个指令是LOAD B,就是将1111地址的数据读取到寄存器B中。(转化为十进制就是15)

⚡3. 执行指令
找到15这个地址上的数据,读取到寄存器B中了,接着程序计数器就更新为2
⚡1. 读取指令
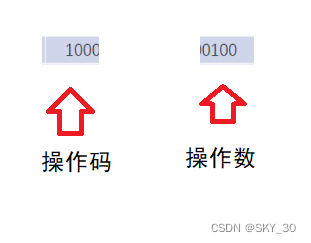
⚡ 2. 解析指令
计算两个指定寄存器的数据之和,并将结果放到第二个寄存器中
⚡3. 执行指令
程序计数器自动更新++
🌅🌅🌅1) 读取指令
🌅🌅🌅2)解析指令
🌅🌅🌅3)执行指令
将结果存入到1101->13中去,程序计数器++
后面的指令我们通过指令表可以看到全部为零此时我们认为该指令执行完毕。
⚡⚡⚡操作系统的进程管理

对于操作系统来说,有很多重要的核心参数,在这其中就有一个非常重要的参数叫进程,即用来描述一个程序运行情况,一般情况下,一个程序以exe文件的形式躺在硬盘中,当我们点击运行它的时候,就会被读取到内存中,进而将指令传入到CPU中。
进程是操作系统分配资源的基本单位,由于电脑中的进程是非常多的,所以要进行管理,通常以类似于结构体的形式,将这些进程即其中的属性描述出来,每个进程之间以链表的形式存储,后面我们打开一个程序,或者结束一个程序,对应的就是链表的插入和删除。对于Linux来说就是以一个叫PCB的结构体描述进程信息的。
🌈🌈🌈PCB中的重要参数
⚡⚡⚡PID
每个进程的标识符,不会重复,系统中的很多操作都是依据PID找到相应的进程的。
⚡⚡⚡内存指针
用来描述一个进程依赖的指令和数据在那个区域
⚡⚡⚡文件描述符表
用来描述一个进程打开了哪些文件(硬盘中的),结构类似于顺序表,打开一个文件,就插入一个元素,从侧面体现了进程的执行需要一定的硬盘资源。
🌈🌈🌈进程的调度
当你打开自己的任务管理器,观察自己机器的进程的时候,会发现其实系统中运行的进程有百八十个,但是我们的计算机只有6核12线程也就是只能执行12个进程,那这到底是咋回事呢,这就涉及到一个重要的知识"进程的分时复用"

此时CPU会分时运行进程一,过一会运行进程二,再过一会运行进程三,由于CPU的运行和切换速度非常快,我们肉眼难以观察到,所以站在人的角度认为CPU运行进程是并发执行
现在的多核CPU,每个核心与核心之间会执行不同的进程,这就是CPU的并行执行。
我们一般将并发执行和并行执行合称为并发执行,对应的编程手法称为并发编程。
⚡⚡⚡进程的状态
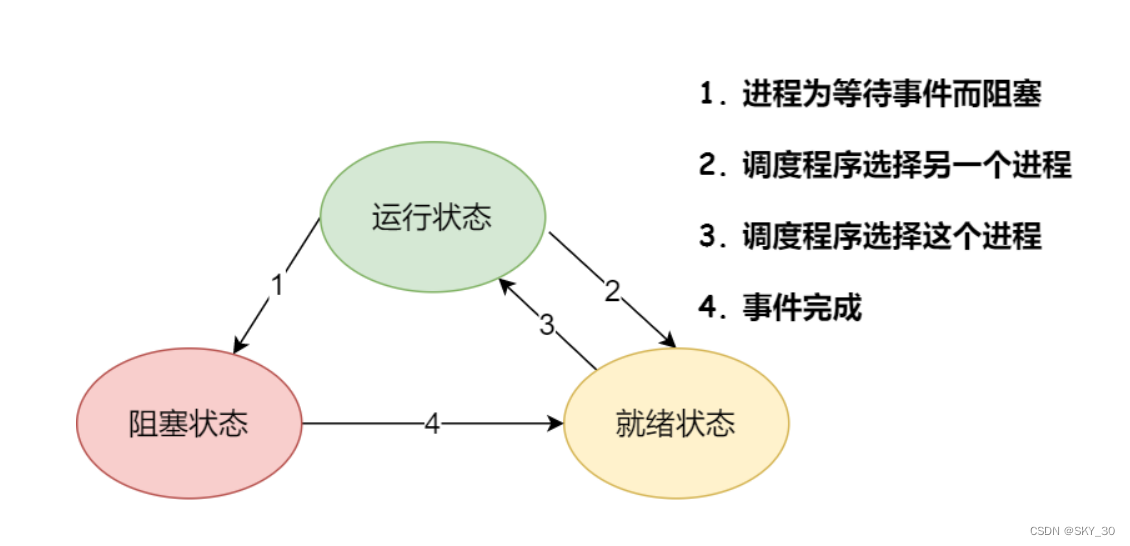
就绪状态的进程,是可以随时被调度到CPU上执行指令的
而阻塞的进程无法被调度到CPU执行,因为要做一些其他的工作,比如IO操作,例如我们编程的时候经常用到的scanf和Scanner
⚡⚡⚡进程的优先级
每个进程的优先级是不一样,正如我们上面所说,CPU执行进程是分时复用的,所以执行的过程一定有一个优先级,这就表示这个进程何时被执行,占用CPU多少时间。
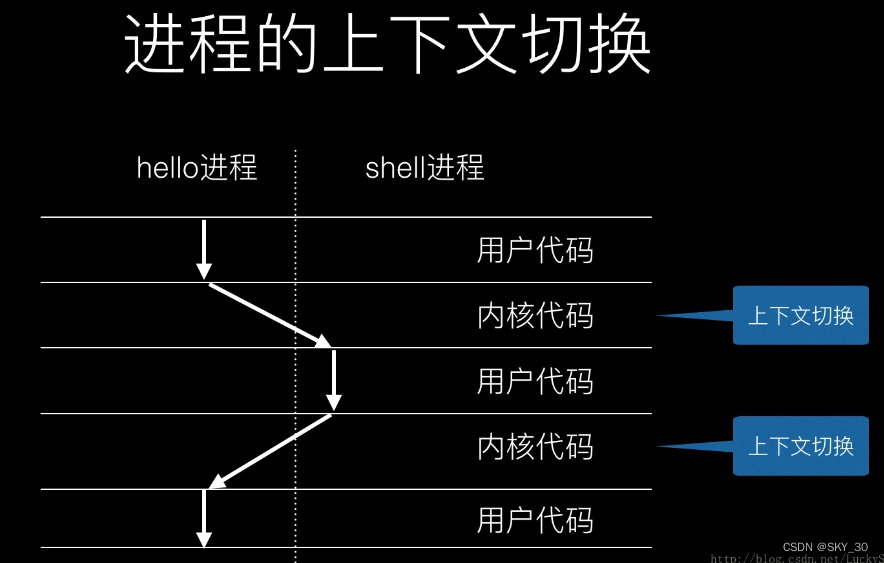
⚡⚡⚡进程的上下文
由于我们对于众多的进程采用分时复用,那么当结束一个进程时势必要将该进程的信息存储下来,不然下次运行该进程的时候,就会遗忘之前的信息,导致运行错误。
⚡⚡⚡进程的记账信息
在优先级的加持下,不同的进程吃到的资源差距越来越大,为了不影响进程的正常运行,CPU会统计每个进程运行的时间,依据这个重新完成调度的调整。
这几个属性相互配合,共同完成进程的调度的核心逻辑。