网站建设的功能特点有哪些网站流量分析报告

前 言
写这篇教程的初衷是很多朋友都想了解如何入门/转行网络安全,实现自己的“黑客梦”。文章的宗旨是:
1.指出一些自学的误区
2.提供客观可行的学习表
3.推荐我认为适合小白学习的资源.大佬绕道哈!
→点击获取网络安全资料·攻略←
一、自学网络安全学习的误区和陷阱
1.不要试图先成为一名程序员(以编程为基础的学习)再开始学习
我在之前的回答中,我都一再强调不要以编程为基础再开始学习网络安全,一般来说,学习编程不但学习周期长,而且实际向安全过渡后可用到的关键知识并不多
一般人如果想要把编程学好再开始学习网络安全往往需要花费很长时间,容易半途而废。而且学习编程只是工具不是目的,我们的目标不是成为程序员。建议在学习网络安全的过程中,哪里不会补哪里,这样更有目的性且耗时更少
2.不要把深度学习作为入门第一课
很多人都是冲着要把网络安全学好学扎实来的,于是就很容易用力过猛,陷入一个误区:就是把所有的内容都要进行深度学习,但是把深度学习作为网络安全第一课不是个好主意。原因如下:
- 深度学习的黑箱性更加明显,很容易学的囫囵吞枣
- 深度学习对自身要求高,不适合自学,很容易走进死胡同
3.不要收集过多的资料
网上有很多关于网络安全的学习资料,动辄就有几个G的材料可以下载或者观看。而很多朋友都有“收集癖”,一下子购买十几本书,或者收藏几十个视频
网上的学习资料很多重复性都极高而且大多数的内容都还是几年前没有更新。在入门期间建议“小而精”的选择材料,下面我会推荐一些自认为对小白还不错的学习资源,耐心往下看
二、学习网络安全的一些前期准备
1.硬件选择
经常会有私信问我“学习网络安全需要配置很高的电脑吗?”答案是否定的,黑客用的电脑,不需要什么高的配置,只要稳定就行.因为黑客所使用的一些程序,低端CPU也可以很好的运行,而且不占什么内存.还有一个,黑客是在DOS命令下对进行的,所以电脑能使用到最佳状态!所以,不要打着学习的名义重新购买机器…
2.软件选择
很多人会纠结学习黑客到底是用Linux还是Windows或者是Mac系统,Linux虽然看着很酷炫,但是对于新人入门并不友好。Windows系统一样可以用虚拟机装靶机来进行学习
至于编程语言,首推Python,因为其良好的拓展支持性。当然现在市面上很多网站都是PHP的开发的,所以选择PHP也是可以的。其他语言还包括C++、Java…
很多朋友会问是不是要学习所有的语言呢?答案是否定的!引用我上面的一句话:学习编程只是工具不是目的,我们的目标不是成为程序员
(这里额外提一句,学习编程虽然不能带你入门,但是却能决定你能在网络安全这条路上到底能走多远,所以推荐大家自学一些基础编程的知识)
3.语言能力
我们知道计算机最早是在西方发明出来的,很多名词或者代码都是英文的,甚至现有的一些教程最初也是英文原版翻译过来的,而且一个漏洞被发现到翻译成中文一般需要一个星期的时间,在这个时间差上漏洞可能都修补了。而且如果不理解一些专业名词,在与其他黑客交流技术或者经验时也会有障碍,所以需要一定量的英文和黑客专业名词(不需要特别精通,但是要能看懂基础的)
比如说:肉鸡、挂马、shell、WebShell等等
三、网络安全学习路线
第一阶段:基础操作入门
入门的第一步是学习一些当下主流的安全工具课程并配套基础原理的书籍,一般来说这个过程在1个月左右比较合适。
第二阶段:学习基础知识
在这个阶段,你已经对网络安全有了基本的了解。如果你学完了第一步,相信你已经在理论上明白了上面是sql注入,什么是xss攻击,对burp、msf、cs等安全工具也掌握了基础操作。这个时候最重要的就是开始打地基!
所谓的“打地基”其实就是系统化的学习计算机基础知识。而想要学习好网络安全,首先要具备5个基础知识模块:

学习这些基础知识有什么用呢?
计算机各领域的知识水平决定你渗透水平的上限。
- 比如:你编程水平高,那你在代码审计的时候就会比别人强,写出的漏洞利用工具就会比别人的好用;
- 比如:你数据库知识水平高,那你在进行SQL注入攻击的时候,你就可以写出更多更好的SQL注入语句,能绕过别人绕不过的WAF;
- 比如:你网络水平高,那你在内网渗透的时候就可以比别人更容易了解目标的网络架构,拿到一张网络拓扑就能自己在哪个部位,拿到以一个路由器的配置文件,就知道人家做了哪些路由;
- 再比如你操作系统玩的好,你提权就更加强,你的信息收集效率就会更加高,你就可以高效筛选出想要得到的信息
第三阶段:实战操作
1.挖SRC
挖SRC的目的主要是讲技能落在实处,学习网络安全最大的幻觉就是觉得自己什么都懂了,但是到了真的挖漏洞的时候却一筹莫展,而SRC是一个非常好的技能应用机会。
2.从技术分享帖(漏洞挖掘类型)学习
观看学习近十年所有0day挖掘的帖,然后搭建环境,去复现漏洞,去思考学习笔者的挖洞思维,培养自己的渗透思维
最后如果你对网络安全感兴趣的话,可以去点击领取资料。
给大家的福利
零基础入门
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。
1️⃣零基础入门
① 学习路线
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。
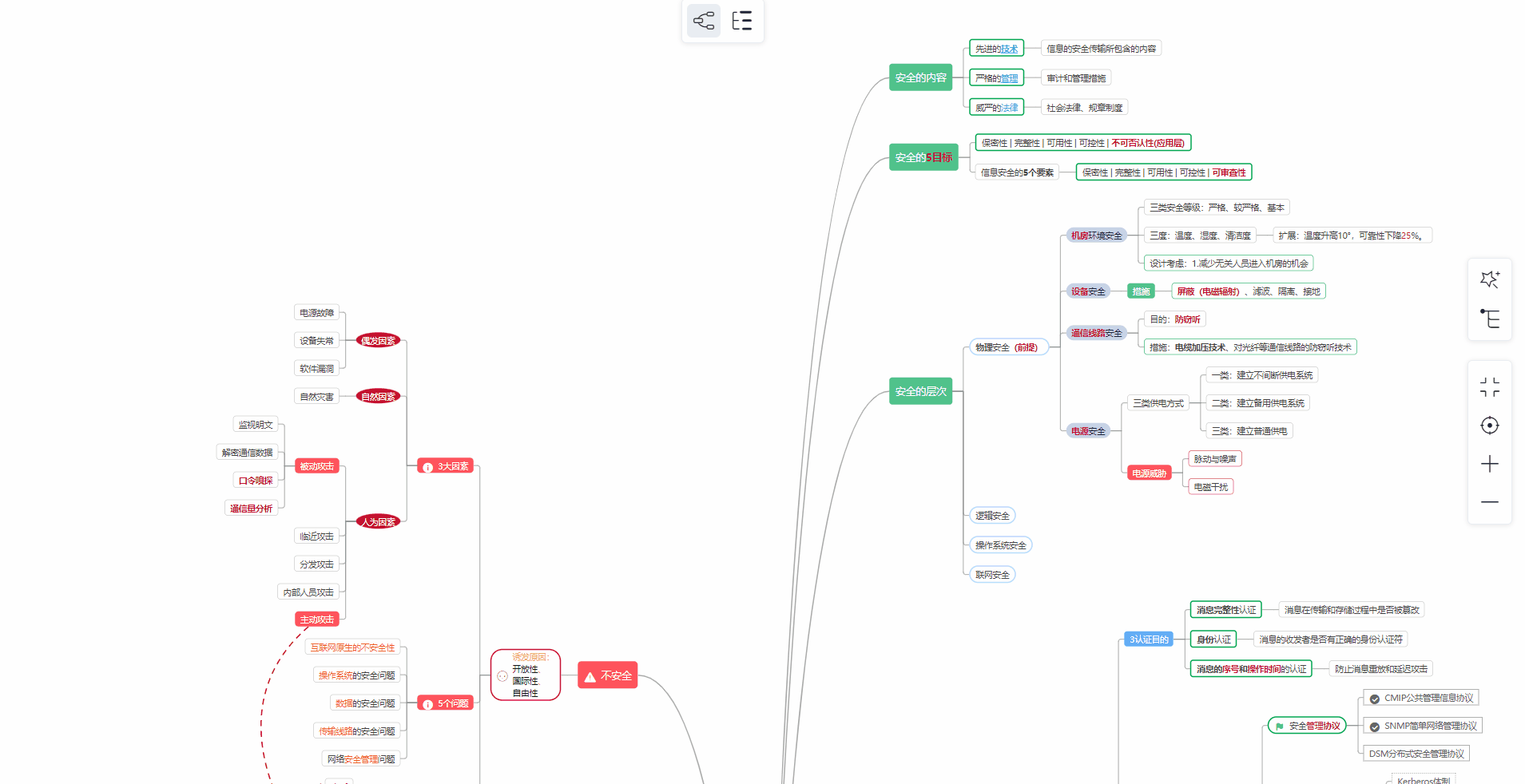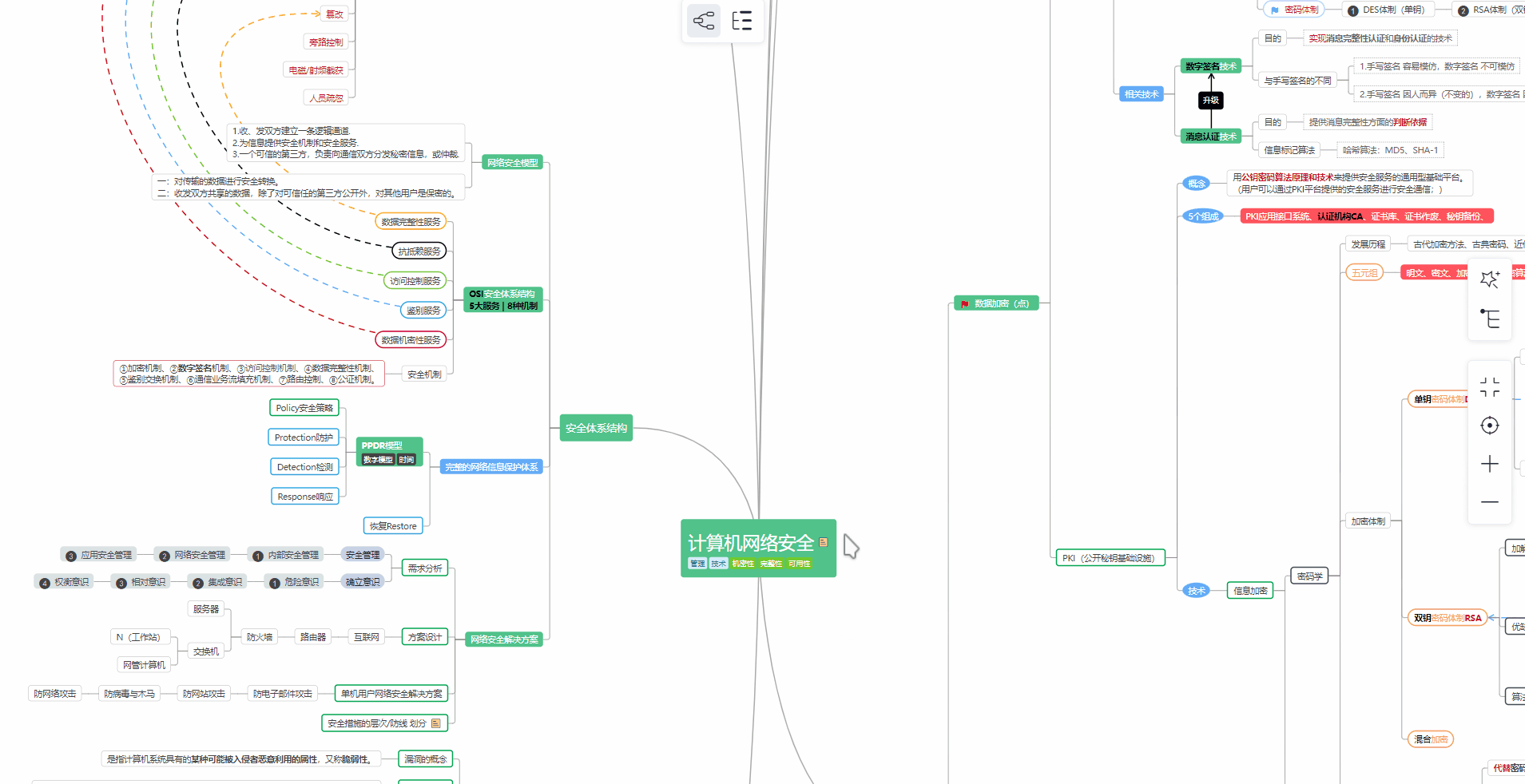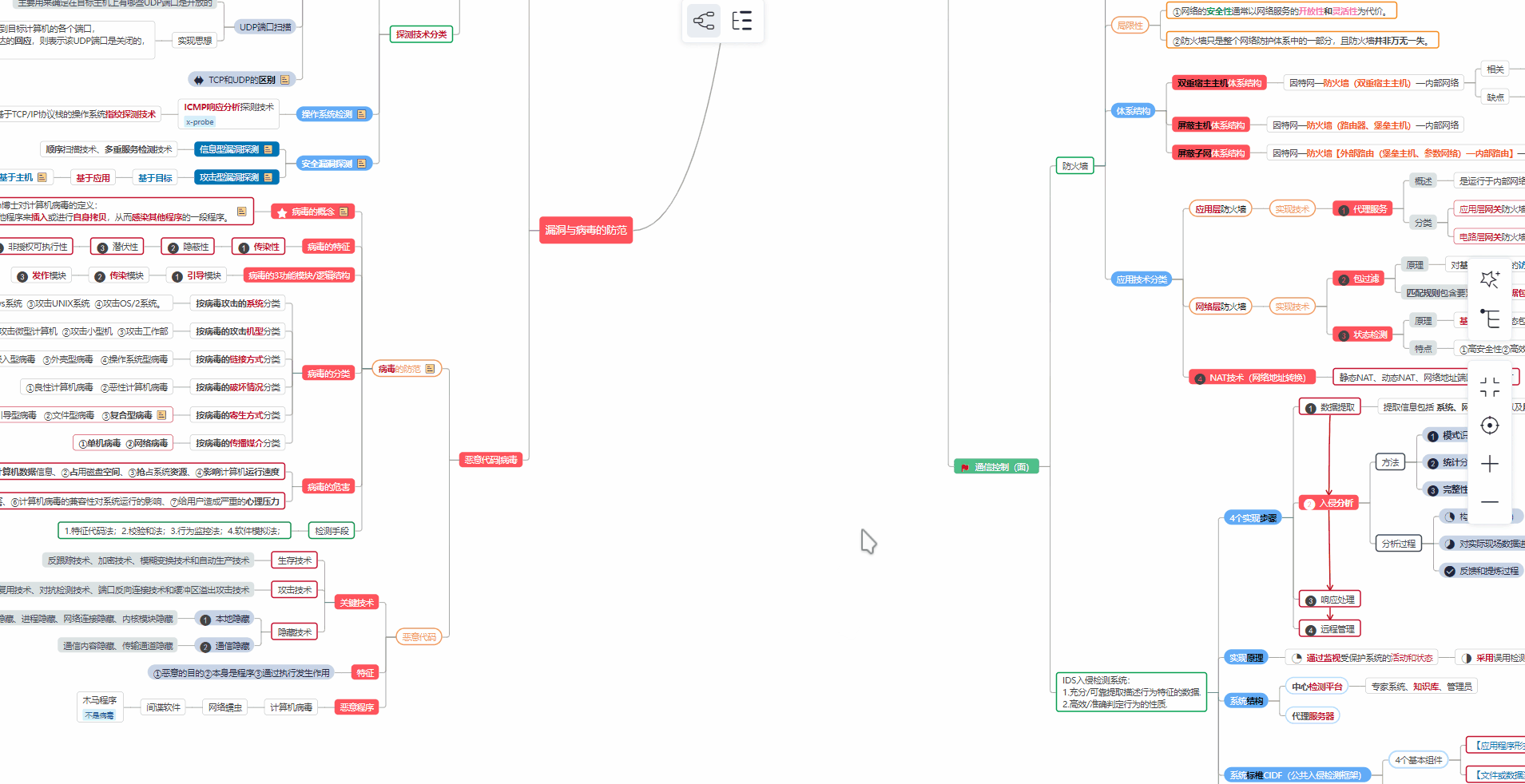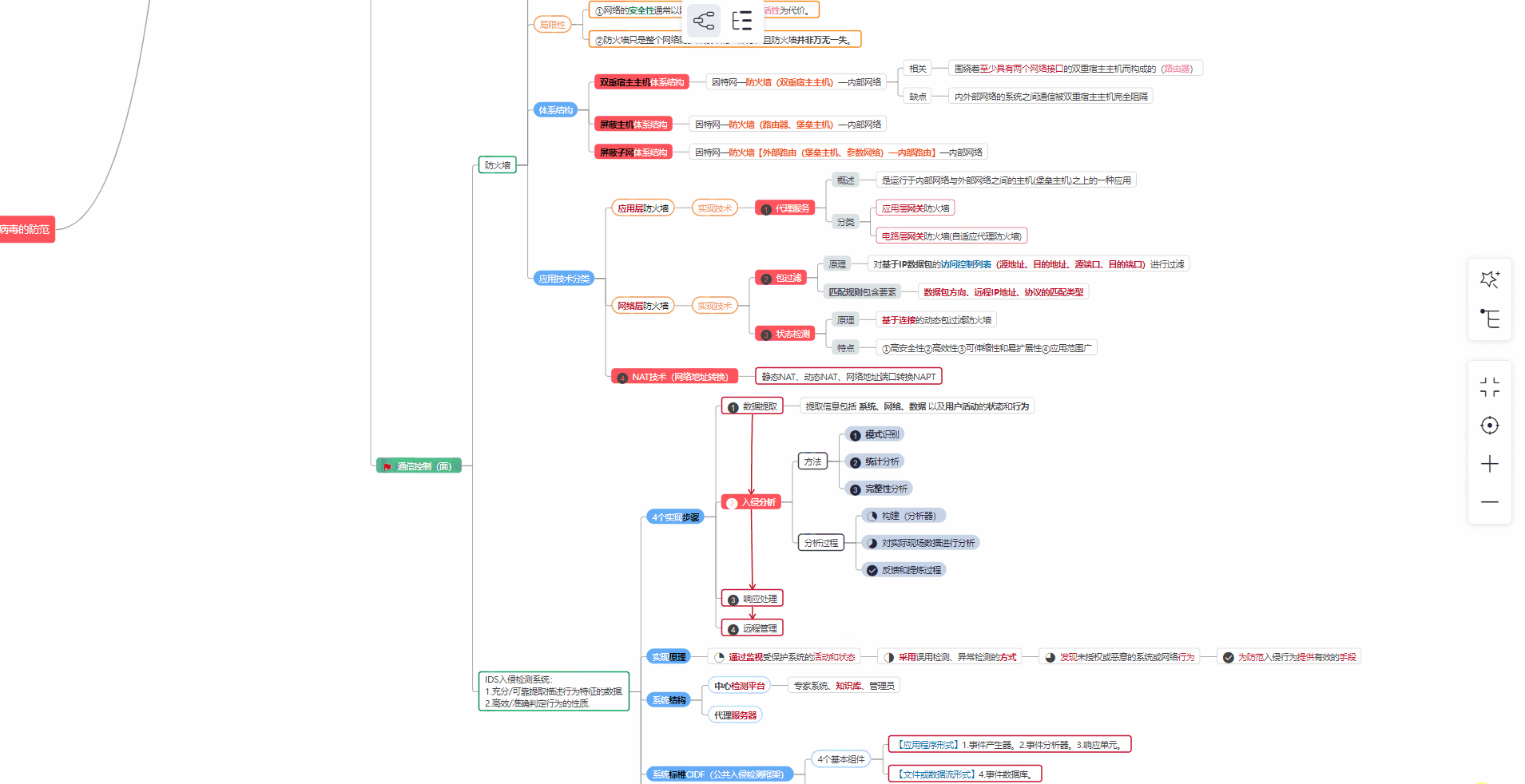
② 路线对应学习视频
同时每个成长路线对应的板块都有配套的视频提供:
因篇幅有限,仅展示部分资料

2️⃣视频配套资料&国内外网安书籍、文档
① 文档和书籍资料
② 黑客技术

因篇幅有限,仅展示部分资料
4️⃣网络安全面试题

5️⃣汇总
所有资料 ⚡️ ,朋友们如果有需要全套 《网络安全入门+进阶学习资源包》,扫码获取~
