呼市城乡建设厅网站出词

博主介绍:✌全网粉丝3W+,全栈开发工程师,从事多年软件开发,在大厂呆过。持有软件中级、六级等证书。可提供微服务项目搭建与毕业项目实战,博主也曾写过优秀论文,查重率极低,在这方面有丰富的经验✌
博主作品:《Java项目案例》主要基于SpringBoot+MyBatis/MyBatis-plus+MySQL+Vue等前后端分离项目,可以在左边的分类专栏找到更多项目。《Uniapp项目案例》有几个有uniapp教程,企业实战开发。《微服务实战》专栏是本人的实战经验总结,《Spring家族及微服务系列》专注Spring、SpringMVC、SpringBoot、SpringCloud系列、Nacos等源码解读、热门面试题、架构设计等。除此之外还有不少文章等你来细细品味,更多惊喜等着你哦
🍅开源项目免费哦(有vue2与vue3版本): 点击这里克隆或者下载 🍅
🍅文末获取联系🍅精彩专栏推荐订阅👇🏻👇🏻 不然下次找不到哟
Java项目案例《100套》
https://blog.csdn.net/qq_57756904/category_12173599.html
uniapp小程序《100套》
https://blog.csdn.net/qq_57756904/category_12199600.html
●若某文件系统的目录结构如下图所示,假设用户要访问文件fl.java,且当前工作目录为Program,则该文件的全文件名为(24),其相对路径为(25)。
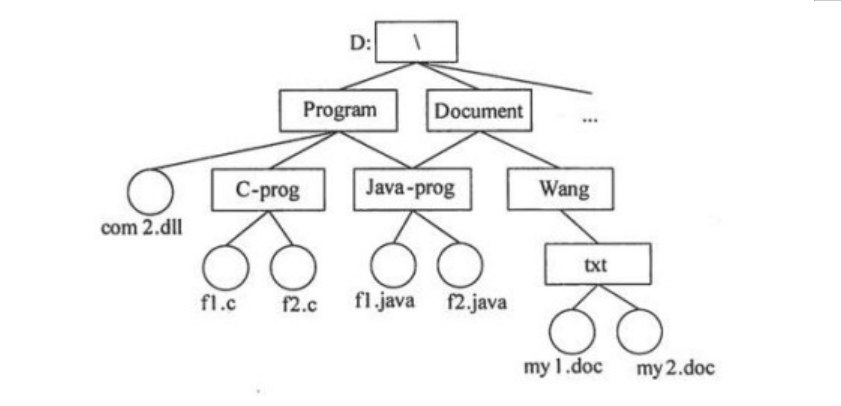
(24)A.fl.java B.\Document\Java-prog\fl.java
C.D:\Program\Java-prog\fl .java D.\Program\Java-prog\fl .java
(25)A.Java-prog\ B.\Java-prog\
C.Program\Java-prog D.\Program\Java-prog\
●假设磁盘每磁道有18个扇区,系统刚完成了10号柱面的操作,当前移动臂在13号柱面上,进程的请求序列如下表所示。若系统采用SCAN (扫描)调度算法,则系统响应序列为(26);若系统采用CSCAN(单向扫描)调度算法,则系统响应序列为(27)。
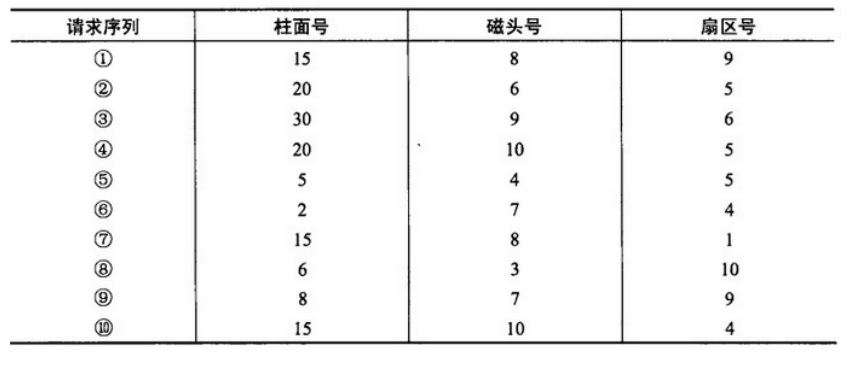
(26)A.⑦⑩①②④③⑨⑧⑤⑥ B.①⑦⑩②③④⑥⑤⑧⑨
C.⑦⑩①②④③⑥⑤⑧⑨ D.①⑦⑩②③④⑧⑨⑥⑤
(27)A.⑦⑩①②④③⑨⑧⑤⑥ B.①⑦⑩②③④⑥⑤⑧⑨
C.⑦⑩①②④③⑥⑤⑧⑨ D.①⑦⑩②③④⑧⑨⑥⑤
●某程序设计语言规定在源程序中的数据都必须具有类型,然而,(28)并不是做出此规定的理由。
(28)A.为数据合理分配存储单元
B.可以定义和使用动态数据结构
C.可以规定数据对象的取值范围及能够进行的运算
D.对参与表达式求值的数据对象可以进行合法性检查
●以下关于喷泉模型的叙述中,不正确的是(29)。
(29)A.喷泉模型是以对象作为驱动的模型,适合于面向对象的开发方法
B.喷泉模型克服了瀑布模型不支持软件重用和多项开发活动集成的局限性
C.模型中的开发活动常常需要重复多次,在迭代过程中不断地完善软件系统
D.各开发活动(如分析、设计和编码)之间存在明显的边界试题
●若全面采用新技术开发一个大学记账系统,以替换原有的系统,则宜选择采用(30)进行开发。
(30)A.瀑布模型 B.演化模型 C.螺旋模型 D.原型模型
●将每个用户的数据和其他用户的数据隔离开,是考虑了软件的(31)质量特件。
(31)A.功能性 B.可靠性 C.可维护性 D.易使用性
●在软件评审中,设计质量是指设计的规格说明书符合用户的要求。设计质量的评审内容不包括(32)。
(32)A.软件可靠性 B.软件的可测试性 C.软件性能实现情况 D.模块层次
●针对应用在运行期的数据特点,修改其排序算法使其更高效,属于(33)维护。
(33)A.正确性 B.适应性 C.完善性 D.预防性
●下图所示的逻辑流实现折半查找功能,最少需要(34)个测试用例可以覆盖所有的可能路径。
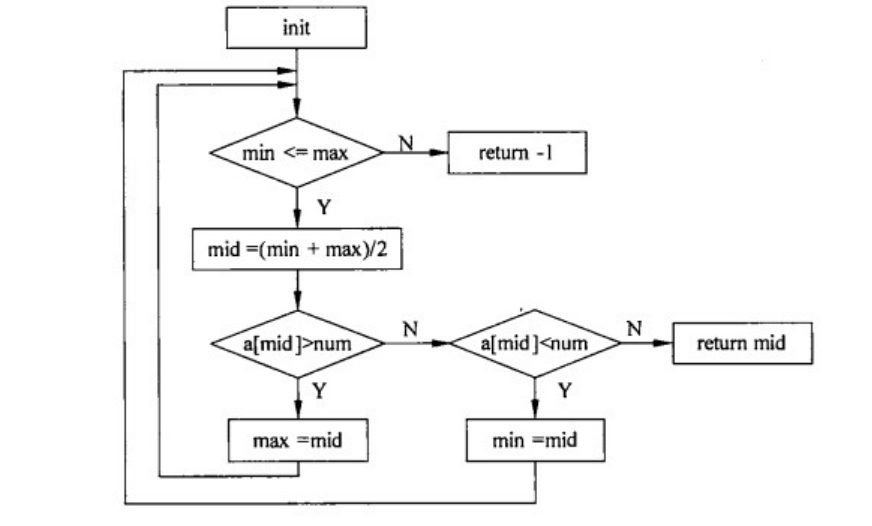
(34)A.1 B.2 C.3 D.4
●在某班级管理系统中,班级的班委有班长、副班长、学习委员和生活委员,且学生年龄在15〜25岁。若用等价类划分来进行相关测试,则(35)不是好的测试用例。
(35)A.(队长,15) B.(班长,20) C.(班长,15) D.(队长,12)
●进行防错性程序设计,可以有效地控制(36)维护成本。
(36)A.正确性 B.适应性 C.完善性 D.预防性
●采用面向对象开发方法时,对象是系统运行时基本实体。以下关于对象的叙述中,正确的是(37)。
(37)A.对象只能包括数据(属性) B.对象只能包括操作(行为)
C.对象一定有相同的属性和行为 D.对象通常由对象名、属性和操作三个部分组成
●一个类是(38)在定义类时,将属性声明为private的目的是(39)。
(38)A.一组对象的封装 B.表示一组对象的层次关系
C.一组对象的实例 D.—组对象的抽象定义
(39)A.实现数据隐藏,以免意外更改 B.操作符重载
C.实现属性值不可更改 D.实现属性值对类的所有对象共享
●(40)设计模式允许一个对象在其状态改变时,通知依赖它的所有对象。该设计模式的类图如下图,其中,(41)在其状态发生改变时,向它的各个观察者发出通知。
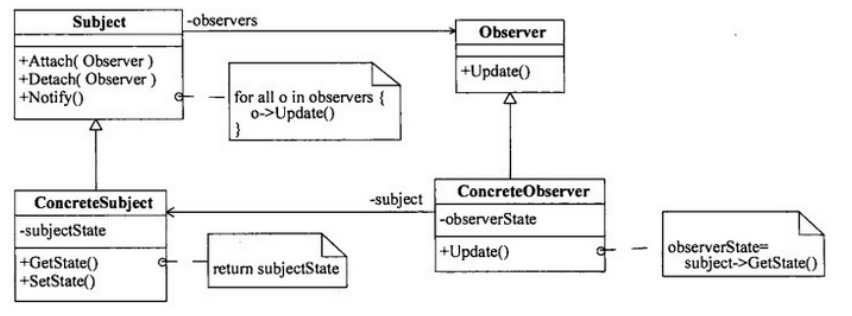
(40)A.命令(Command) B.责任链(Chain of Responsibility)
C.观察者(Observer) D.迭代器(Iterator)
(41)A.Subject B.ConcreteSubject C.Observer D.ConcreteObserver
●在面向对象软件开发中,封装是一种(42)技术,其目的是使对象的使用者和生产者分离。
(42)A.接口管理 B.信息隐藏 C.多态 D.聚合
●欲动态地给一个对象添加职责,宜采用(43)模式。
(43)A.适配器(Adapter) B.桥接(Bridge)
C.组合(Composite) D.装饰器(Decorator)
●(44)模式通过提供与对象相同的接口来控制对这个对象的访问。
(44)A.适配器(Adapter) B.代理(Proxy)
C.组合(Composite) D.装饰器(Decorator)
●采用UML进行面向对象开发时,部署图通常在(45)阶段使用。
(45)A.需求分析 B.架构设计 C.实现 D.实施
●业务用例和参与者一起描述(46),而业务对象模型描述(47)。
(46)A.工作过程中的静态元素 B.工作过程中的动态元素
C.工作过程中的逻辑视图 D.组织支持的业务过程
(47)A.业务结构 B.结构元素如何完成业务用例
C.业务结构以及结构元素如何完成业务用例 D.组织支持的业务过程
●下图所示为一个有限自动机(其中,A是初态、C是终态),该自动机识别的语言可用正规式(48)表示。
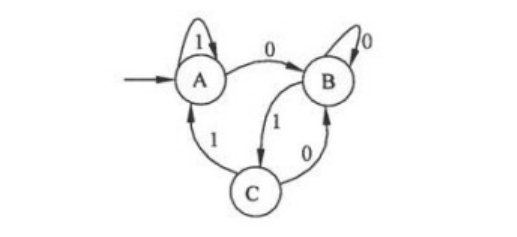
(48)A.(0|1)*01 B.1*0*10*1 C.1*(0)*01 D.1*(0|10)*1*
●函数t、f的定义如下所示,其中,a是整型全局变量。设调用函数t前a的值为5, 则在函数t中以传值调用(call by value)方式调用函数f时,输出为(49)在函数f中以引用调用(callby reference)方式调用函数f时,输出为(50)。
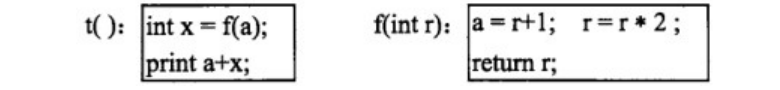
●将Students表的插入权限赋予用户UserA,并允许其将该权限授予他人,应使用的SQL语句为: GRANT (51) TABLE Students TO UserA (52);
(51)A.UPDATE B.UPDATE ON C.INSERT D.INSERT ON
(52)A.FOR ALL B.PUBLIC
C.WITH CHECK OPTION D.WITH GRANT OPTION